AI Deep Dive
Dec 11, 2024
•
5 min read
Agents and Data Reasoning: Overcoming the Limitations of RPA

Quick Primer
Robotic Process Automation (aka RPA) has been heavily relied upon by enterprises to help automate repetitive, rule-based tasks. By using technology to mimic every day tasks, RPA has delivered efficiency gains and cost savings in processes that were traditionally time-consuming and labor-intensive. However as modern businesses continue evolve over time, RPA’s inherent limitations have become more evident. In order to stay competitive, companies must address these shortfalls and explore complementary solutions that push automation beyond simple task execution.
Today, we’ll explore the limitations of RPA, how agents and data reasoning can address these challenges, and the essential steps companies need to take to harness this next wave of technology.
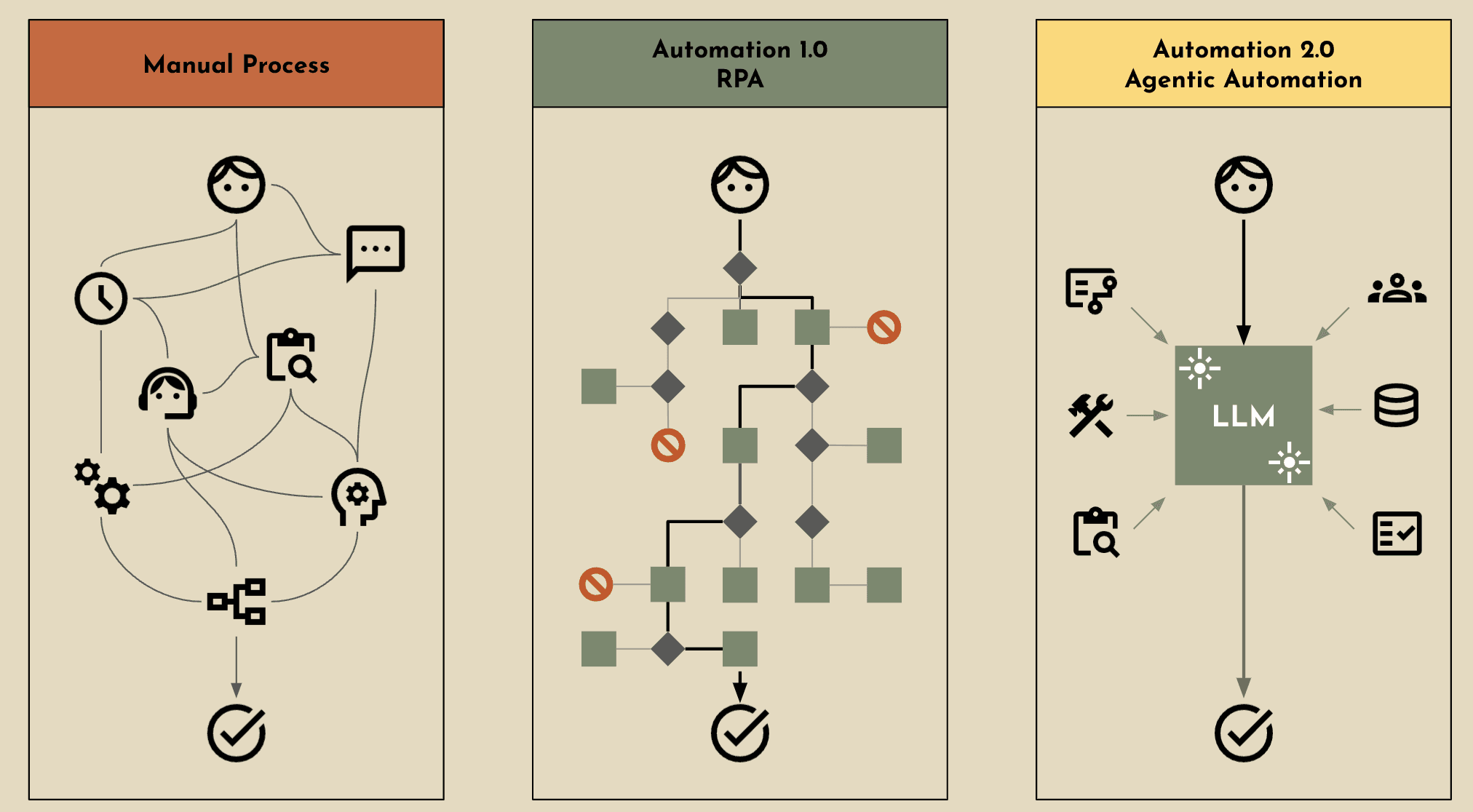
Where RPA Falls Short
While RPA excels at handling repetitive, rule-based tasks, most enterprise workflows are far more complex and involve multi-step processes. In a recent study by Gartner, the survey showed that while RPA can automate tasks, it often struggles with scalability across complex, enterprise-wide operations, leading to increased maintenance and integration challenges. Roughly 48% of RPA projects fail due to excessive complexity, while 30% tend to fail due to the lack of context that’s required to conduct the task.
It’s safe to say that the success rate of automation drops significantly as complexity rises, with successful implementations becoming the exception rather than the norm. So what exactly are the shortcomings when it comes to RPA?
Performance - Rule-Based Tasks: RPA is designed for structured, repetitive processes and cannot handle tasks requiring judgment or decision-making.
Performance - Prone to Errors: RPA automates flawed processes without identifying or correcting errors, potentially amplifying inaccuracies.
Performance - Inability to Process Unstructured Data: RPA tends to struggle with data formats like emails, PDFs, images, or free-form text, limiting its application scope.
Performance - Lacks Contextual Understanding: RPA performs tasks without understanding their broader context, which limits its ability to prioritize or reason.
Scalability - Lack of Adaptability and Requires Maintenance: RPA bots require reprogramming for any changes in workflows, making them rigid in dynamic environments. This means that updates and monitoring are constantly required to keep workflows functioning properly, which increases overhead.
Scalability - Ineffectiveness with Complex Processes: When it comes to RPA, workflows are generally a single track, lacking the ability to navigate multi-step workflows or tasks that require intermediate conclusions and dynamic logic.
The Emergence of Intelligent Agents and Data Reasoning
Over the past year, the term "AI agents" has become just as prominent as "AI" itself. For those unfamiliar, an AI agent is a software program designed to perform tasks autonomously on behalf of a user, with intelligence that mimics human-like behavior. These agents can analyze data, make decisions, and learn from their interactions and experiences, enabling them to improve and adapt their performance over time. With agents, enterprise companies can overcome RPA’s shortfalls including:
Performance - Rule-Based Tasks: Agents can handle complex, multi-step tasks that require decision-making, reasoning, and context-awareness. They excel in workflows that involve dynamic inputs or require real-time adjustments
Performance - Prone to Errors: Agents can continuously learn and improves performance throughout the process - adapting autonomously to match the evolving workflows and environments.
Performance - Inability to Process Unstructured Data: Agents leverage LLMs (large language models) that can help analyze both structured and unstructured data. Whereas RPA may have challenges breaking down unstructured data, agents can leverage a variety of techniques to process the data.
Performance - Lacks Contextual Understanding: An AI agent understands context and relationships, enabling smarter decisions and task prioritization.
Scalability - Lack of Adaptability and Requires Maintenance: With agents, there’s a reduction when it comes to maintenance since it adapts autonomously to changes within the systems or within the process.
Scalability - Ineffectiveness with Complex Processes: Agents manage complex, multi-step workflows by using it’s dynamic decision-making capabilities.
With these unique capabilities, AI agents introduce a new era of automation, performing tasks intelligently and autonomously without human intervention—a concept we call agentic automation or automation 2.0.
However agents are just one part of the equation when it comes to automation. The true power lies in the data itself and how it’s utilized to create meaningful outcomes. In other words, it’s about the logic applied to the data—what we call data reasoning. Data reasoning is the practice of analyzing, interpreting, and applying logic to data, in order to draw insights that can help deliver informed decision-making. It goes beyond basic data collection and analysis by focusing on understanding the why behind the what. At Gradient, we like to describe this as moving from basic operational tasks to higher order operational tasks. Unlike basic operational tasks—which might handle simple calculations or aggregations—data reasoning takes it a step further, using advanced operations to interpret data and help you integrate your institutional knowledge back into your workflows. This can involve uncovering relationships between data points, forecasting future trends, analyzing sentiment, or integrating unstructured data from various sources to produce actionable insights.
In essence, data reasoning requires more than just access to data; it requires the ability to process, interpret, and derive meaning from data in ways that align with specific business goals. And by data, we mean all types—both structured and unstructured. This process is especially valuable in cases where data alone cannot yield straightforward answers but requires deeper analysis and contextual understanding to guide decisions.
If you’re interested in seeing whether or not data reasoning is right for your organization, you can find out by answering these 5 questions here. Or if you’re interested in learning a bit more about the various levels of complexity when it comes to data reasoning, you can checkout our breakdown here.
So Are Agents and Data Reasoning the Answer?
In short, yes—but with some important factors to consider especially if you’re using traditional methods and techniques. While agents and data reasoning represent a significant advancement in automation, enterprise businesses should take the following into consideration. Deploying agents into production can be complex, and overcoming these hurdles is essential to unlocking their full potential. The primary challenges lie in the need for technical expertise, ensuring data accessibility, and managing the inherent complexities of applying logic to data effectively.
1. Technical Depth and Resourcing
Working with AI agents demands a significant level of technical expertise, often requiring a multidisciplinary team that includes machine learning engineers, data scientists, software developers, and domain specialists. Building, training, and maintaining AI agents is a far cry from deploying rule-based systems like RPA. For instance, creating an agent capable of real-time fraud detection or personalized customer interactions requires expertise in natural language processing, predictive modeling, and integration with existing systems. While doable, not every enterprise company will have the resources to make it happen.
In short, adopting initiatives like these often requires a significant upfront investment, particularly for organizations starting from scratch. Without the necessary technical expertise, many companies struggle to implement production-ready AI solutions, turning these opportunities into aspirational goals rather than practical realities.
2. The Data Dilemma: Accessibility and Structure
Despite advancements in AI, significant challenges remain around data—particularly in processing, accessing, and preparing unstructured information. With an estimated 80% of enterprise data being unstructured, this data holds valuable insights yet often goes untapped due to its complexity. Organizations frequently face obstacles like siloed systems, legacy databases, and inconsistent data formats, making it difficult to extract the clean, cohesive datasets AI agents require to perform effectively.
For example, while an AI agent might be capable of analyzing customer sentiment from emails and social media, extracting this data from disparate sources and ensuring it’s properly formatted for analysis is a labor-intensive process. This complexity is exacerbated in industries like financial services, where sensitive data must also meet strict compliance standards, adding another layer of difficulty to data accessibility.
3. The Complexity of Data Reasoning
Even with a fully staffed technical team and access to well-prepared data, applying reasoning and logic to that data is complicated. The challenge with data reasoning is that it’s inherently complex. Real-world data is not ideal. As we mentioned earlier, it can be noisy, incomplete, unstructured or inconsistent - posing significant challenges to teams that have to work with this data. On top of that, distinguishing between correlation and causation requires deep expertise and careful methodology. Which means that you’ll need a unique blend of analytical prowess, domain knowledge, and critical thinking if this is something you want to pursue. Unlike static algorithms, AI agents are expected to operate in dynamic environments where decisions must account for uncertainty and constantly evolving data.
For instance, in asset management, an AI agent tasked with portfolio optimization must weigh multiple variables—market trends, risk profiles, and investor preferences—while adapting to real-time changes. This level of reasoning requires not only advanced algorithms but also an understanding of the domain, as applying logic without context can lead to inaccurate or suboptimal decisions.
Simplify Data Reasoning with Gradient
So to answer your question on whether or not there’s an easier way to deal with these challenges, the answer is yes. The team at Gradient developed the first AI-powered Data Reasoning Platform, that’s designed to automate and transform how enterprises handle their most complex data workflows. Powered by a suite of proprietary large language models (LLMs) and AI tools, Gradient eliminates the need for manual data preparation, intermediate processing steps, or a dedicated ML team to maximize the ROI from your data. Unlike traditional data processing tools, Gradient’s Data Reasoning Platform doesn’t require teams to create complex workflows from scratch and manually tune every aspect of the pipeline.
Schemaless Experience: The Gradient Platform provides a flexible approach to data by removing traditional constraints and the need for structured input data. Enterprise organizations can now leverage data in different shapes, formats, and variations without the need to prepare and standardize the data beforehand.
Deeper Insights, Less Overhead: Automating complex data workflows with higher order operations has never been easier. Gradient’s Data Reasoning Platform removes the need for dedicated ML teams, by leveraging AI to take in raw or unstructured data to intelligently infer relationships, derive new data, and handle knowledge-based operations with ease.
Continuous Learning and Accuracy: Gradient’s Platform implements a continuous learning process to improve accuracy that involves real-time human feedback through the Gradient Control System (GCS). Using GCS, enterprise businesses have the ability to provide direct feedback to help tune and align the AI system to expected outputs.
Reliability You Can Trust: Precision and reliability are fundamental for automation, especially when you’re dealing with complex data workflows. The Gradient Monitoring System (GMS) identifies anomalies that may occur to ensure workflows are consistent or corrected if needed.
Designed to Scale: Typically the more disparate data you have, the bigger the team you’ll need to process, interpret, and identify key insights that are needed to execute high level tasks. Gradient enables you to process 10x the data at 10x the speed without the need for a dedicated team or additional resourcing.
Even with limited, unstructured or incomplete datasets, the Gradient Data Reasoning Platform can intelligently infer relationships, generate derived data, and handle knowledge-based operations - making this a completely unique experience. This means that teams can automate even the most intricate workflows at the highest level of accuracy and speed - freeing up valuable time and overhead.
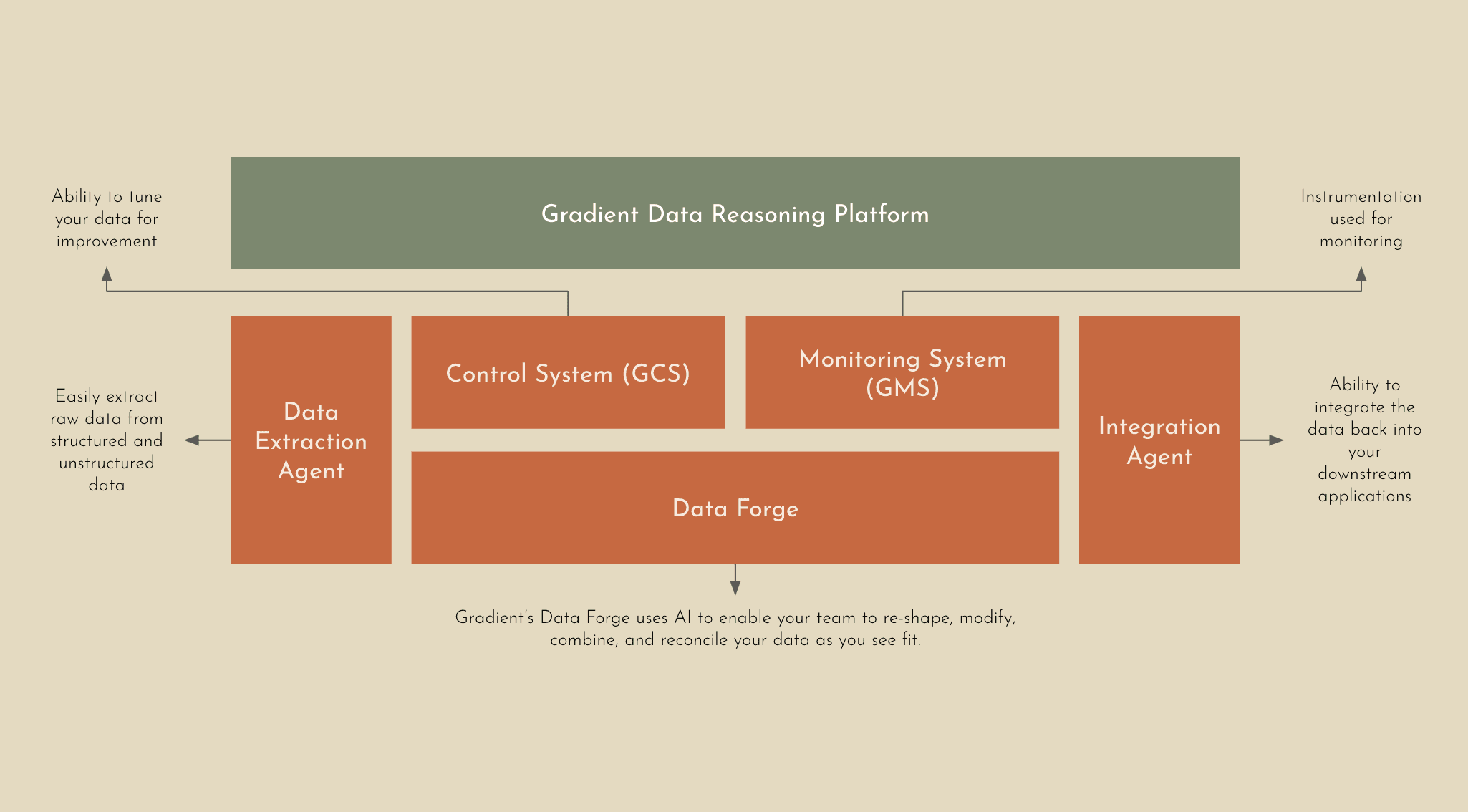
Under the Hood: What Makes it Possible
The magic of the Gradient Data Reasoning Platform is its high accuracy, quick time to value, and easy integration into existing enterprise systems.
Data Extraction Agent: Our Extraction Agent intelligently ingests and parses any type of data into Gradient without hassle, including raw and unstructured data. Whether you’re working with PDFs or PNGs we’ve got you covered.
Data Forge: This is the heart of the Gradient Platform. AI automatically reasons about your data - re-shaping, modifying, combining, and reconciling your structured and unstructured data via higher order operations to achieve your objective. Our Data Forge leverages advanced agentic AI techniques to guide the models through multi-hop reasoning reliably and accurately - contextualizing the institutional data and grounding it to elicit the best output.
Integration Agent: When your data is ready, Gradient will ensure that your data can be easily integrated back into your downstream applications via a simple API.
With Gradient, businesses can focus on the outcomes—whether it’s driving customer insights, ensuring regulatory compliance, or optimizing production lines—without getting bogged down in the operational intricacies of data workflows. By automating complex data workflows, organizations can achieve faster, more accurate results at scale - reducing costs and enhancing operational efficiency. In a world where data complexity continues to grow, the ability to harness that data through automation is not just a competitive advantage—it’s a necessity.
Share
Tags