Archive
Jun 7, 2023
Can We Prompt an LLM to Uncover its Dreams of Electric Sheep?

However, the complete theory of these abilities still eludes us, and achieving it may rely on developing new interpretive mathematical frameworks well beyond our current understanding. In the absence of these frameworks, or as a preliminary step towards them, we must explore the capabilities of LLMs through experimental means. One such method by which we can probe an LLM very effectively is by prompting. This spurs the question: what fundamental capabilities can be revealed about LLMs through the process of prompting?
To explore this question, we begin by delving into the fundamentals of prompting and how prompting can enhance the performance of an LLM on complex reasoning tasks. We also highlight how prompting, while shown to be a valuable technique to improve the performance of an LLM, is not sufficient to fully unlock the capabilities of an LLM. Lastly, we explore how prompting can be coupled with other techniques to improve and augment datasets which enables vast improvements for fine-tuning an LLM. Throughout our discussion, we draw from the ever-growing literature on the subject, providing a narrative that highlights the current understanding and explores potential avenues for further exploration.
Note: This narrative by no means provides a complete synthesis of the vast literature on LLMs and prompting techniques. We invite discussion in the comments on additional research that illustrates or calls to question the concepts presented in this post.
What’s in a Prompt?
Let’s start by establishing some definitions: a prompt is an input provided to a large language model (LLM) with the intention of eliciting a specific type of response. Typically, prompts are concise pieces of text, such as a few sentences or a paragraph, that offer context and guidance for the model to generate a response. It’s worth noting that there have been successful experiments with longer prompts as well. The content and structure of a prompt can vary significantly depending on the task and the specific requirements of the model. For instance, in a question-answering task, a prompt would typically include a question that the model is expected to answer, along with any relevant facts or information to support the response.
While there is a wide range of prompt variations, an effective prompting technique generally consists of three components: a meta-prompt, exemplars, and a template. The purpose of meta-prompting is to guide the model in generating high-quality responses, while the exemplars and template contribute similar content and formatting style for the response. To achieve an optimal combination of these three parts, it is essential to carefully align the content and structure of the prompt with the specific capabilities and limitations of the LLM being used.

A simple example of a few-shot prompting technique for answering math questions on the GSM8K dataset.
This particular prompting format, known as few-shot prompting, has garnered attention due to its remarkable effectiveness, even without extensive modifications. It has demonstrated the ability to significantly enhance model performance across various tasks [1]. One crucial aspect of this technique is the importance of elucidative exemplars that are appropriately matched to the task, such as exemplars of reasoning paths for reasoning tasks. This latter approach, commonly called chain-of-thought prompting, has proven highly effective for larger models in achieving exceptional performance both on reasoning tasks and simple question-answering tasks [2]. However, it should be noted that smaller models may require more refined techniques and extensive elaborations on chain-of-thought prompting to achieve a comparable level of performance. For further insights and examples of refinements in this area, refer to [3], [4], [5], [6], and [7].
Can we make LLMs Reason?
The short answer is no, at least not in the same way that we expect formal verification systems to. The generation process of an LLM is associative and probabilistic, and current prompting and fine-tuning techniques only serve to constrain the space of generation without even a mathematical theory to measure convergence to effective reasoning paths. However, there are valuable insights we can gain from present techniques:
Self-Consistency [8]: Sampling diverse reasoning paths and using a majority vote for a numeric answer can improve performance in chain-of-thought prompting for arithmetic reasoning tasks. While it doesn’t provide a way to verify an answer is correct, this approach offers “high-confidence” outputs and leverages the understanding that complex reasoning problems often have multiple valid solutions.
Self-Improvement [9]: Fine-tuning on self-generated datasets without labels can enhance performance on complex reasoning tasks. Note that despite potential errors in data generation, the model can still improve with sufficient high-quality data with this technique.
Self-Ask [10], Reflexion [11], and Self-Refinement [12]: Modifying self-generated datasets by additional prompting can improve performance on complex reasoning tasks. In these techniques, reinforced feedback and elaborate prompting both improve the quality and complexity of reasoning paths and allow for better validation.
Although these techniques have been shown to be effective, all of them ultimately have two notable limitations. First, as reasoning tasks become more complex (n-hop reasoning), prompting becomes less effective. Second, once an LLM memorizes information, it struggles to unpack its reasoning chains and reason about smaller subtasks. Unfortunately, these two challenges are contradictory: longer prompts can improve reasoning chains but lead to decreased performance on simpler tasks. See [13], [14], and [15] for further details. See also the very recent paper [16] for how OpenAI achieved state-of-the-art performance on mathematical reasoning.
Meta-Prompting, aka, the Humanculus
The precise mechanics of meta-prompting remains one of the most elusive challenges to understand for uncovering an LLM’s behavior. To illustrate the inherent difficulty, we can turn to the philosophical homunculus argument, which highlights the inadequacy of explaining a complex phenomenon by invoking a smaller version of the same phenomenon. In other words, simply attributing the functioning of an LLM to an internal “agent” that performs the desiderata of the meta-prompt becomes circular or necessitates an infinite regression.
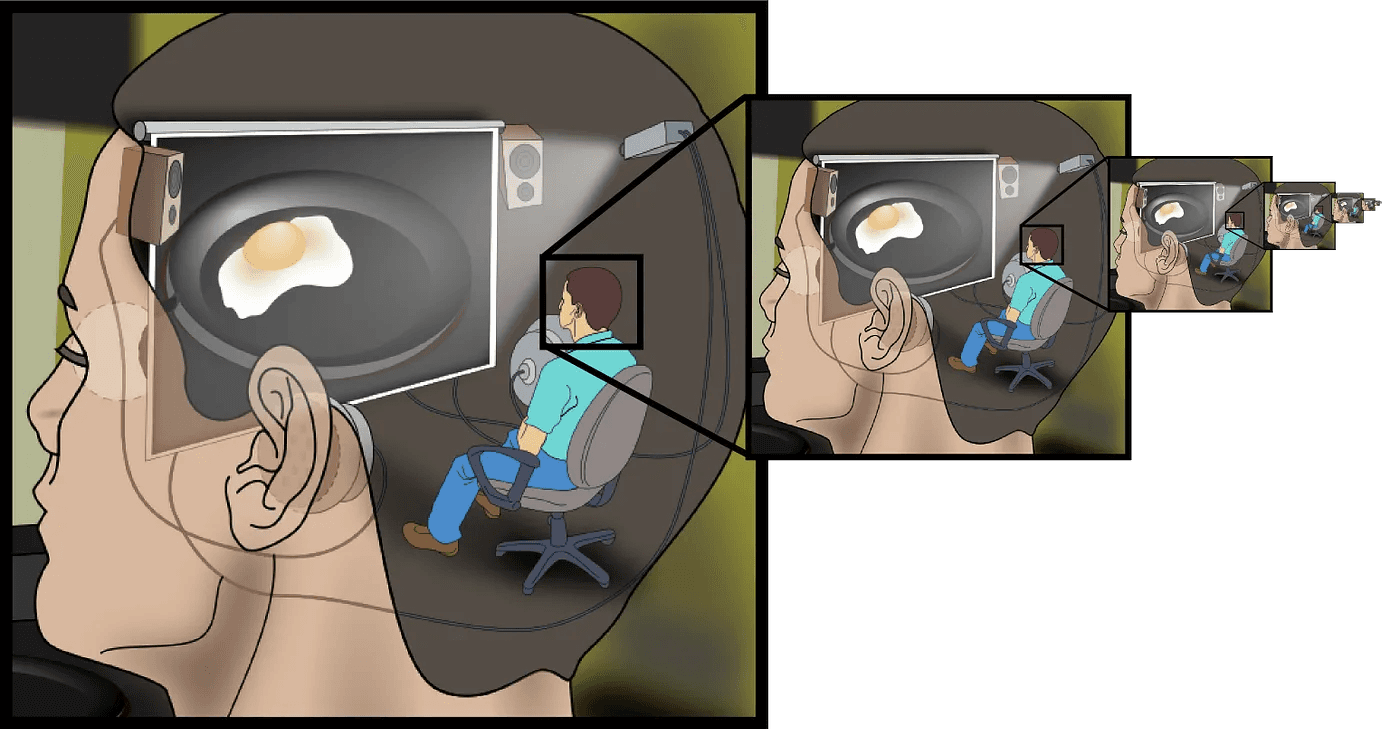
An illustration of infinite regress for the homunculus argument in the context of the human visual cortex. Scientifically, homunculus arguments are considered fallacious unless one can prove grounds for regress. [17]
The precise word choice, grammar, or semantics of a meta-prompt can vastly alter an LLM’s performance or quality of output on a task. We can employ two LLM-based approaches to improve the quality of a meta-prompt: refining a human-generated meta-prompt in dialogue with an LLM or architecting a meta-meta-prompt to generate a more precisely tailored meta-prompt [18], [19]. However, it is crucial to note that both approaches still require a human in the loop (even if the human-generated input has been abstracted a level away from directly generating the meta-prompt), and the effectiveness of the meta-prompt still ultimately hinges on the intuition and expertise of the human involved in the process. In essence, LLMs rely on the interaction with human judgment and guesswork to guide prompt generation — that is, with a humanculus that guides the model capability.
A theory towards identifying optimal meta-prompts would take into account the inherent structure of the language model and uncover inherent words or phrases that link to specific outputs; this would ultimately be wrapped in a sophisticated mathematical framework if possible. While the mechanisms of meta-prompting still remain to be explored as an inherent model phenomenon, some suggestive research that approach understanding language models in this way include:
DetectGPT [20], which aims to identify whether a given passage of text has been generated by an LLM by defining a curvature-based criterion for determining if a text passage originates from a specific LLM. What makes DetectGPT interesting is that it does not require training a separate classifier, creating a dataset of real or generated passages, or adding explicit watermarks to the generated text; it relies only on the log probabilities computed by the LLM itself.
Automatic Prompt Optimization [21], which aims to automate the process of prompt optimization using training data to guide the editing of the prompt in the opposite semantic direction of a “prompt gradient”, effectively refining vague task descriptions to more precise annotation instructions for a specific LLM. This technique has significantly outperformed other prompt editing techniques and is even useful for detecting LLM jailbreak.
In general, though, this area remains highly under-explored and encompasses a multitude of complex questions that we have yet to fully comprehend or even to articulate effectively.
Prompting for Generating Synthetic Datasets
One of the early instances of using of few-shot prompting to generate synthetic datasets that gained the spotlight was the Self-Instruct method [22] which transformed a LLaMa [23] into an Alpaca [24]. The approach is straightforward: start with a small seed dataset of 175 exemplars, iteratively generate more data by few-shot prompting, and increase the diversity of the generated dataset by filtering the output by the Rouge-L score. Although simple, the insights from this method highlight the immense potential of synthetic dataset generation to complement and enhance existing human-generated datasets, and ultimately lead to improved performance of LLMs. Notably, the variability observed in the synthetic dataset, measured by the Rouge-L score, hints at the necessity of incorporating significant mathematical complexity in datasets to effectively enhance model performance. On the other hand, the absence of any metrics to assure data quality during the generation of the synthetic dataset suggests that reasonably good performance can still be achieved even with minor errors.
More detailed studies such as [25], [26], and [27] have further validated these insights from Self-Instruct. Moreover, researchers have found additional approaches to enriching dataset complexity that have yet to be firmly grounded in mathematical rigor. For instance, repetition in datasets has been observed to negatively impact model performance [28], while incorporating multiple diverse reasoning paths for the same question has demonstrated improvements in subsequent composability tasks — see [8], [29]. This type of complexity, which we will refer to as semantic complexity, cannot be measured merely by symbolic or word-based metrics such as Rouge-L. A thorough understanding of complexity and data quality assurance in the context of synthetic data generation is still an area of extensive exploration. Nevertheless, it is evident that the insights to be gained from assessing dataset quality relates to the insights we gain from effective prompting.
In a noteworthy study conducted by Microsoft and Peking University [30], it was shown that an LLM that is fine-tuned on a sufficiently complex and diverse synthetic dataset can outperform an LLM that was fine-tuned only on a human-generated dataset. The technique developed here, called Evol-Instruct, used prompting both to modify existing instructions in a human-generated dataset to increase the semantic complexity and to generate entirely new instructions that were equally complex but entirely different from existing instructions to increase the diversity of the dataset. The results are very impressive, but a detailed comparison of the mathematical complexity between the synthetically-generated and human-generated datasets remains to be explored.
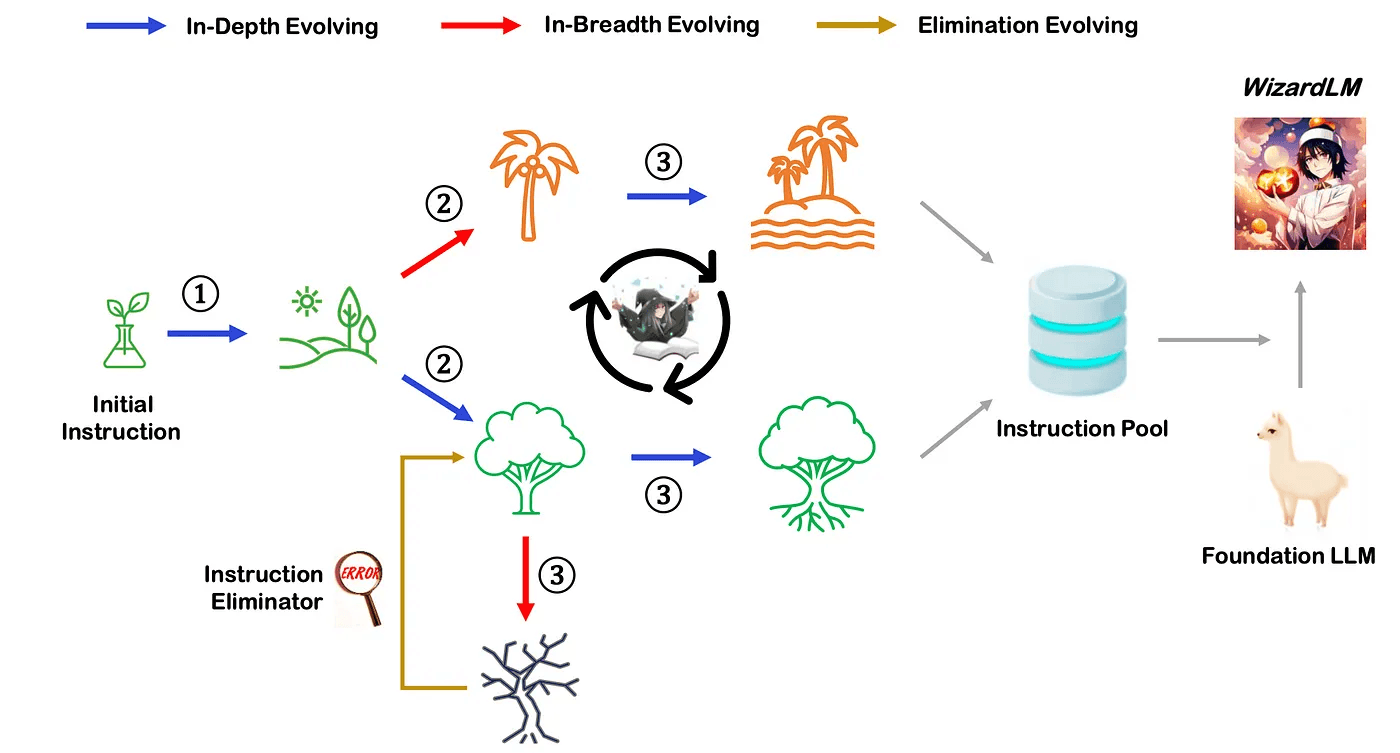
Figure 2 from [30] depicting the Evol-Instruct method.
Recently, there have been an explosion of ever-more refined techniques for using prompting to generate synthetic datasets. One area of advancement that has provided interesting results is in the realm of ensembling, which involves leveraging the capabilities of multiple LLMs to enhance the output of a single model through model prompting. A noteworthy result here is FrugalGPT [31], which cascades multiple LLMs of varying sizes to improve upon the generation of its predecessor. Ensemble techniques in general still remain relatively unexplored in the context of synthetic data generation and require further careful analysis.
What’s Next?
There are still numerous research questions and opportunities for development in the field of prompting LLMs. Some major milestones that we anticipate include:
The ability to effectively unlearn previously learned information, which is crucial for understanding the capabilities of LLMs in performing well on composability tasks. While there have been some studies in this direction, such as [32] and [33], it is evident that unlearning is currently limited, and the most effective approach is often retraining [34].
The ability to assess the quality of input data, whether the data originates from the LLM itself or from another source. One notable effort in building benchmarks and metrics for a holistic evaluation of LLMs is the open research endeavor by HELM [35]. However, it is important to note that assessing data quality is likely to be highly task and domain specific, and requiring an understanding of both the internal mechanisms of an LLM and the semantic quality of a task within its domain context. Care must be taken to avoid introducing researcher or developer biases and artifacts, as discussed in [36].
The ability to self-validate the veracity or quality of output. While there are prototypes of LLMs employing external plugins, such as [37] and [38], a more accurate model would involve implicitly assigning probabilities to the veracity of new inputs based on internal knowledge and reasoning abilities, similar to how humans assess veracity in a conversation in the absence of a search engine. This development is reminiscent of progressive hinting [39] or of approximating confidence levels in a solution [40], but further exploration is needed to understand the nuances involved and tailor the technique to domain-specific tasks.
References
[1] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
[2] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., and Zhou, D. (2023). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv preprint arXiv:2201.11903.
[3] Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv preprint arXiv:2210.03629.
[4] J. Liu, A. Liu, X. Lu, S. Welleck, P. West, R. Le Bras, Y. Choi, and H. Hajishirzi. (2022). Generated Knowledge Prompting for Commonsense Reasoning. arXiv preprint arXiv:2110.08387.
[5] Zhou, D., Scharli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurmans, D., Cui, C., Bousquet, O., Le, Q. V., and Chi, E. H. (2023). Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. In The Eleventh International Conference on Learning Representations. Retrieved from https://openreview.net/forum?id=WZH7099tgfM
[6] Kıcıman, E., Ness, R., Sharma, A., and Tan, C. (2023). Causal Reasoning and Large Language Models: Opening a New Frontier for Causality. arXiv preprint arXiv:2305.00050.
[7] Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y., and Narasimhan, K. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv preprint arXiv:2305.10601.
[8] Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. (2023). Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv preprint arXiv:2203.11171.
[9] Huang, J., Gu, S. S., Hou, L., Wu, Y., Wang, X., Yu, H., and Han, J. (2022). Large Language Models Can Self-Improve. arXiv preprint arXiv:2210.11610.
[10] Press, O., Zhang, M., Min, S., Schmidt, L., Smith, N. A., and Lewis, M. (2022). Measuring and Narrowing the Compositionality Gap in Language Models. arXiv preprint arXiv:2210.03350.
[11] Shinn, N., Labash, B., and Gopinath, A. (2023). Reflexion: An autonomous agent with dynamic memory and self-reflection. arXiv preprint arXiv:2303.11366.
[12] Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y., Welleck, S., Majumder, B. P., Gupta, S., Yazdanbakhsh, A., and Clark, P. (2023). Self-Refine: Iterative Refinement with Self-Feedback. arXiv preprint arXiv:2303.17651.
[13] Kulshreshtha, S., and Rumshisky, A. (2022). Reasoning Circuits: Few-shot Multihop Question Generation with Structured Rationales.” arXiv preprint arXiv:2211.08466
.[14] Ho, X., Nguyen, A.-K. D., Sugawara, S., and Aizawa, A. (2023). Analyzing the Effectiveness of the Underlying Reasoning Tasks in Multi-hop Question Answering. arXiv preprint arXiv:2302.05963.
[15] Shum, K., Diao, S., and Zhang, T. (2023). Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data. arXiv preprint arXiv:2302.12822.
[16] Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. (2023). Let’s Verify Step by Step. arXiv preprint arXiv:2305.20050.
[17] N/A. (n.d.). Infinite regress of homunculus [Digital image]. In Wikipedia. https://en.wikipedia.org/wiki/Homunculus_argument#/media/File:Infinite_regress_of_homunculus.png
[18] Zhou, Y., Muresanu, A. I., Han, Z., Paster, K., Pitis, S., Chan, H., and Ba, J. (2023). Large Language Models Are Human-Level Prompt Engineers. arXiv preprint arXiv:2211.01910.
[19] Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., and Iwasawa, Y. (2023). Large Language Models are Zero-Shot Reasoners. arXiv preprint arXiv:2205.11916.
[20] Mitchell, E., Lee, Y., Khazatsky, A., Manning, C. D., and Finn, C. (2023). DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature. arXiv preprint arXiv:2301.11305.
[21] Pryzant, R., Iter, D., Li, J., Lee, Y. T., Zhu, C., and Zeng, M. (2023). Automatic Prompt Optimization with “Gradient Descent” and Beam Search. arXiv preprint arXiv:2305.03495.
[22] Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., and Hajishirzi, H. (2022). Self-Instruct: Aligning Language Model with Self Generated Instructions. arXiv preprint arXiv:2212.10560.
[23] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., and Lample, G. (2023). LLaMA: Open and Efficient Foundation Language Models. arXiv preprint arXiv:2302.13971.
[24] Center for Responsible Machine Learning. (2023, March 13). ALPaCA: Algorithmic Performance Calibration for Algorithmic Fairness. Retrieved from https://crfm.stanford.edu/2023/03/13/alpaca.html
[25] Zhang, Z., Zhang, A., Li, M., and Smola, A. (2022). Automatic Chain of Thought Prompting in Large Language Models. arXiv preprint arXiv:2210.03493.
[26] Zelikman, E., Wu, Y., Mu, J., and Goodman, N. D. (2022). STaR: Bootstrapping Reasoning With Reasoning. arXiv preprint arXiv:2203.14465.
[27] Su, H., Kasai, J., Wu, C. H., Shi, W., Wang, T., Xin, J., Zhang, R., Ostendorf, M., Zettlemoyer, L., Smith, N. A., and Yu, T. (2022). Selective Annotation Makes Language Models Better Few-Shot Learners. arXiv preprint arXiv:2209.01975.
[28] Lee, K., Ippolito, D., Nystrom, A., Zhang, C., Eck, D., Callison-Burch, C., and Carlini. N. (2022). Deduplicating Training Data Makes Language Models Better. arXiv preprint arXiv:2107.06499.
[29] Yoran, O., Wolfson, T., Bogin, B., Katz, U., Deutch, D., and Berant, J.. (2023). Answering Questions by Meta-Reasoning over Multiple Chains of Thought. arXiv preprint arXiv:2304.13007.
[30] Xu, C., Sun, Q., Zheng, K., Geng, X., Zhao, P., Feng, J., Tao, C., and Jiang, D. (2023). WizardLM: Empowering Large Language Models to Follow Complex Instructions. arXiv preprint arXiv:2304.12244.
[31] Chen, L., Zaharia, M., and Zou, J. (2023). FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance. arXiv preprint arXiv:2305.05176.
[32] Cha, S., Cho, S., Hwang, D., Lee, H., Moon, T., and Lee, M. (2023). Learning to Unlearn: Instance-wise Unlearning for Pre-trained Classifiers. arXiv preprint arXiv:2301.11578.
[33] Jang, J., Yoon, D., Yang, S., Cha, S., Lee, M., Logeswaran, L., and Seo, M. (2022). Knowledge Unlearning for Mitigating Privacy Risks in Language Models. arXiv preprint arXiv:2210.01504.
[34] Chourasia, R., and Shah, N. (2023). Forget Unlearning: Towards True Data-Deletion in Machine Learning. arXiv preprint arXiv:2210.08911.
[35] Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y., Narayanan, D., Wu, Y., Kumar, A., Newman, B., Yuan, B., Yan, B., Zhang, C., Cosgrove, C., Manning, C. D., Ré, C., Acosta-Navas, D., Hudson, D. A., … Koreeda, Y. (2022). Holistic Evaluation of Language Models. arXiv preprint arXiv:2211.09110.
[36] Schaeffer, R., Miranda, B., and Koyejo, S. (2023). Are Emergent Abilities of Large Language Models a Mirage? arXiv preprint arXiv:2304.15004.
[37] Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., and Scialom, T. (2023). Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv preprint arXiv:2302.04761.
[38] Trivedi, H., Balasubramanian, N., Khot, T., and Sabharwal, A. (2022). Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions. arXiv preprint arXiv:2212.10509.
[39] Zheng, C., Liu, Z., Xie, E., Li, Z., and Li, Y. (2023). Progressive-Hint Prompting Improves Reasoning in Large Language Models. arXiv preprint arXiv:2304.09797.
[40] Zhao, T. Z., Wallace, E., Feng, S., Klein, D., and Singh, S. (2021). Calibrate Before Use: Improving Few-Shot Performance of Language Models. arXiv preprint arXiv:2102.09690.
Share





