Archive
Apr 19, 2023
Fine-tuning the LLaMA model to speak English and Chinese


The new model, which we call Alpaca LoRA 30B, can be instructed with English and Chinese, and performs well in both languages on code generation tasks and creative writing.
To produce this new model, we fine-tuned the 30B-parameter LLaMA model from Meta, which does not have multilingual capabilities, with 50k open-source training examples in English and Chinese generated by GPT-4. We used a parameter-efficient fine-tuning technique called LoRA.
Of course, we did this all using the Gradient platform.
In this post, we’ll explain:
Examples of what this new model can do
How we trained the new model
What you can take away from this result
Example output
Our model, Alpaca LoRA 30B, produces high quality completions in both English and Chinese, for code generation and creative writing.
Here are examples of each.
Code generation
As a code generation task, we asked our model to write an algorithm.
Our model produced the following code, along with an explanation:
As reference, here’s output produced by Alpaca 7B. Alpaca 7B is a well-known model, and was the first model fine-tuned using LoRA. It does have fewer weights than the LLaMA model, so the comparison is not 1:1. We use this example just to show the difference in the format of the output.
Alpaca 7B produced the following code:
As you can see, the output from Alpaca 7B doesn’t include an explanation.
In the next section, we describe how we fine-tuned our model to produce an explanation.
Writing poetry in Chinese
As a creative writing task in Chinese, we asked our model, using instructions in Chinese, to write a poem praising artificial intelligence.
Our model produced the following poem:
For convenience, here’s a translation of the instruction and output above:
We would have included a comparison here, but the novel aspect of our model is that it can produce Chinese.
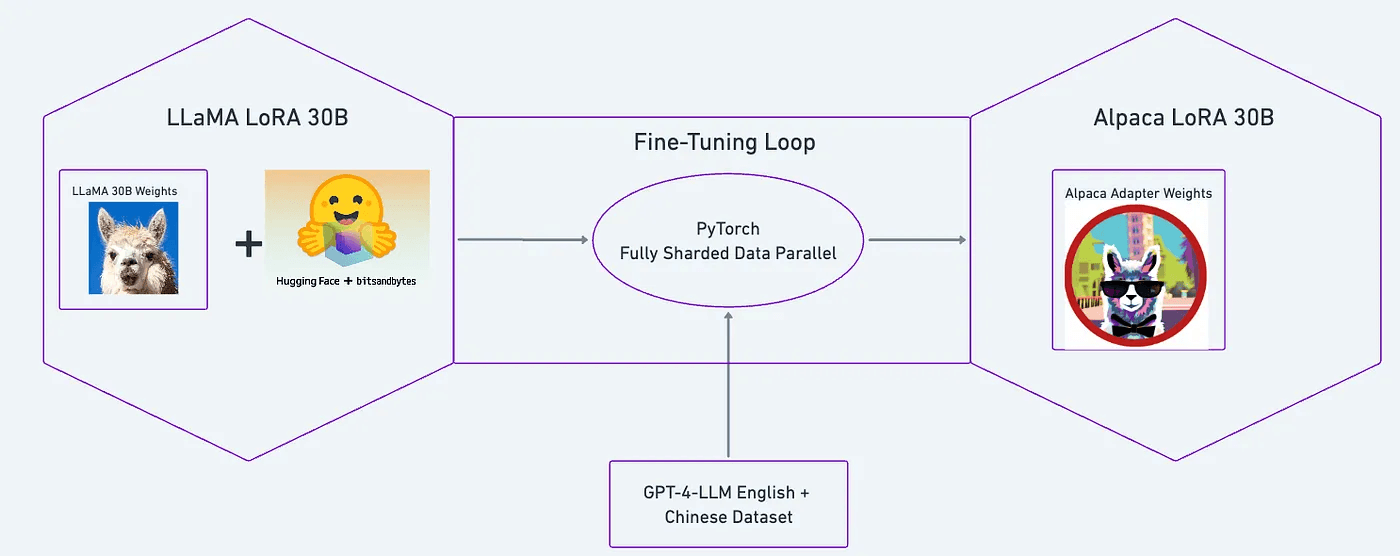
How we did it
In general, a fine-tuning pipeline consists of an input model, fine-tuned on a new dataset, to produce an output model. Here are the details of our pipeline.
Input model
Creating an input model class requires static model weights as well as a model definition — also known as a model architecture. To create our input model class, which we call LLaMA LoRA 30B, we loaded the 30B weights from Meta’s LLaMA model into a LoRA-adapted model architecture that uses HuggingFace transformers and the bitsandbytes library.
Dataset
The English and Chinese datasets we used for fine-tuning came from the paper Instruction Tuning with GPT-4. The paper authors generated synthetic datasets in English and Chinese using GPT-4. Then they used the two datasets individually to fine-tune a model. We combined the two datasets into a single one.
As you can see in the datasets on Github, each example is formatted as: an instruction, an input, and an output. Note that in the dataset, coding questions include explanations as part of the output. Here’s an excerpt:
You can see the impact of these training examples on our fine-tuned model.
Fine-tuning loop with LoRA
Our fine-tuning process leverages LoRA using the same adapter as alpaca-lora.
LoRA is a more efficient fine-tuning technique. In traditional fine-tuning, the weights of the original model are unfrozen and updated. In LoRA, instead of unfreezing the original model, a new layer of weights — called adapter weights — is added.
To quantify the efficiency gain: Meta’s LLaMA model has 30B weights. Our resulting adapter was about 50k weights.
Output model
As explained above, we produced a set of static adapter weights. We call this Alpaca LoRA 30B.
To use this output model to do inference, all you need to do is load the original LLaMA weights along with these adapter weights into the same model architecture. Then you can start generating text completions.
Takeaways
If you want to solve problems that cut across multiple languages, our work suggests a way to create a model that speaks the languages you need.
This quick experiment shows you can produce a model that has multilingual capabilities, by taking a foundational model without these capabilities and fine-tuning it with a dataset in two languages.
Our experiment also suggests parameters can be shared across languages. An interesting question to explore is to what extent combining datasets from different languages can help further generalize a model.
These experiments are all possible today using open-source models and data — if you have the right infrastructure
Using Gradient
At Gradient, we’re building the infrastructure to make running experiments like this easy.
We’re a team familiar with the ins and outs of fine-tuning, and would love to chat with folks we can help — whether you’re just getting started with LLMs or looking to put one into production.
Share





