Archive
Sep 22, 2023
Introducing the Gradient Embeddings API

Introducing the Gradient Embeddings API
We are introducing the Gradient Embeddings API to the Gradient Developer Platform make it easy to perform natural language tasks such as search and classification. This makes it easier for developers to create knowledge bases, no setup required.
This is an exciting addition to our developer platform. Three weeks ago, we launched our Fine-Tuning & Inference API that enables developers to create private, custom LLMs. With the added ability to generate embeddings, our users can continue to build on their models and increase their performance in domain-specific tasks.
What are embeddings?
Embeddings are numerical representations of natural language concepts. A word, phrase or even document is converted into a vector of real numbers. These vectors often have hundreds or thousands of dimensions of relevance. An embeddings model generates these vectors.
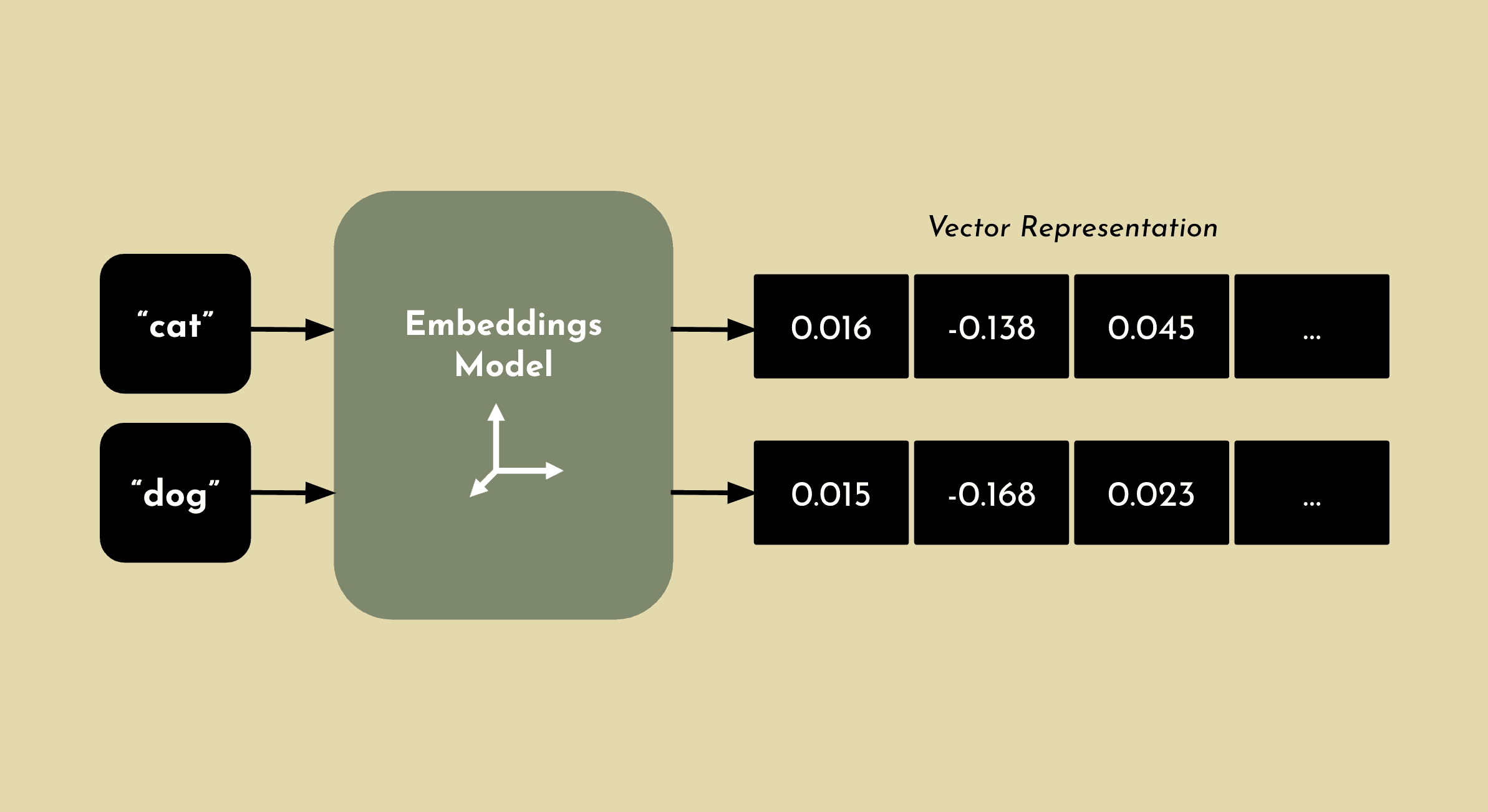
If two concepts are similar, they will also be numerically similar. For example, an embeddings model may not understand that “cat” and “dog” are both pets, but it can determine that they have high semantic similarity and classify them together with other animals that are common pets.
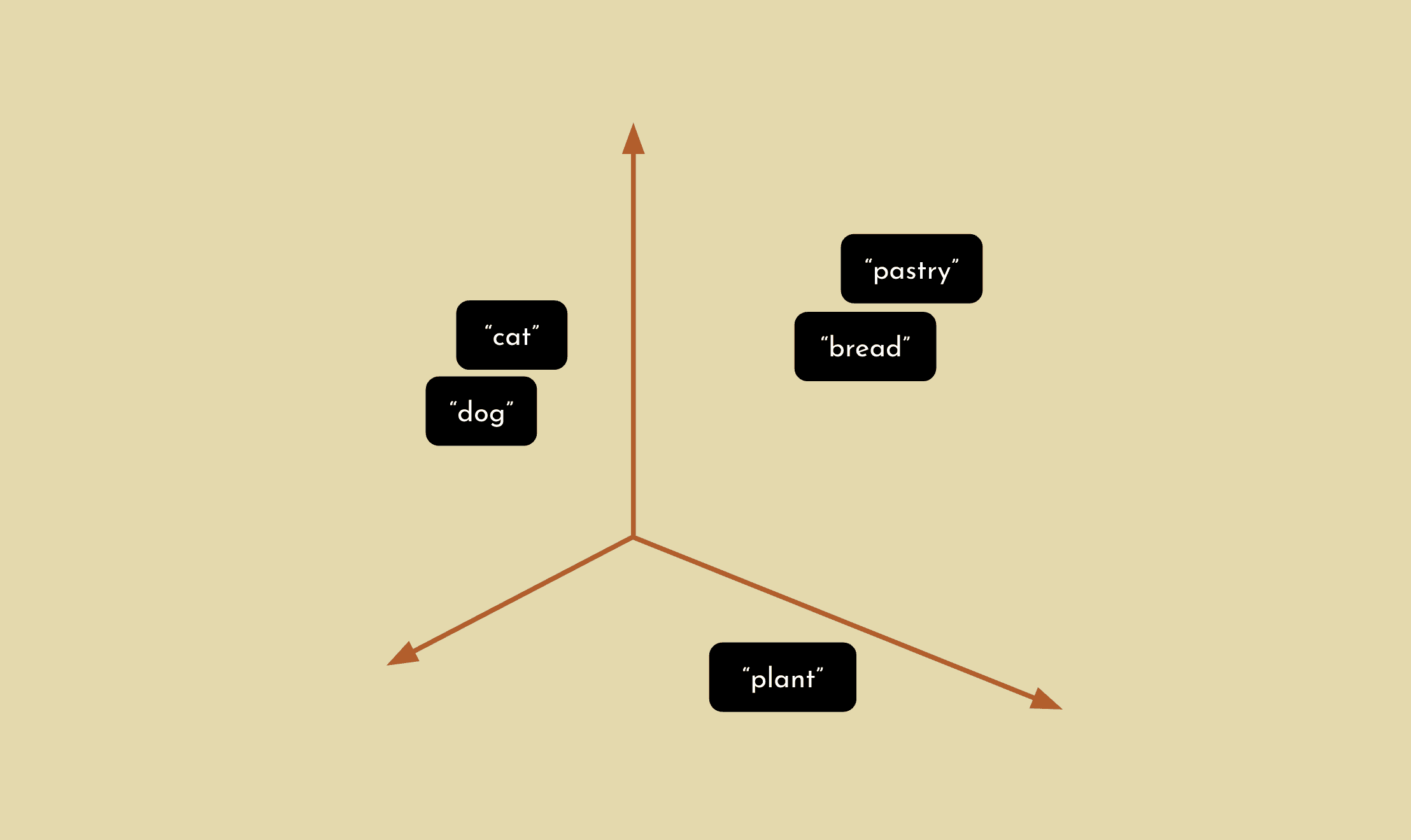
You can imagine these vectors to be plotted in N dimensions. Words that are more semantically similar are “closer” to each other. When you are retrieving relevant information, the model will look at the knowledge base and return information that is “close” to your query.
Introducing Private Gradient Embeddings
We are releasing the Gradient Embeddings API to help you generate embeddings with a simple API call. There is no setup required to start generate embeddings on your data.
The embeddings model will take text as input and return an embedding vector.
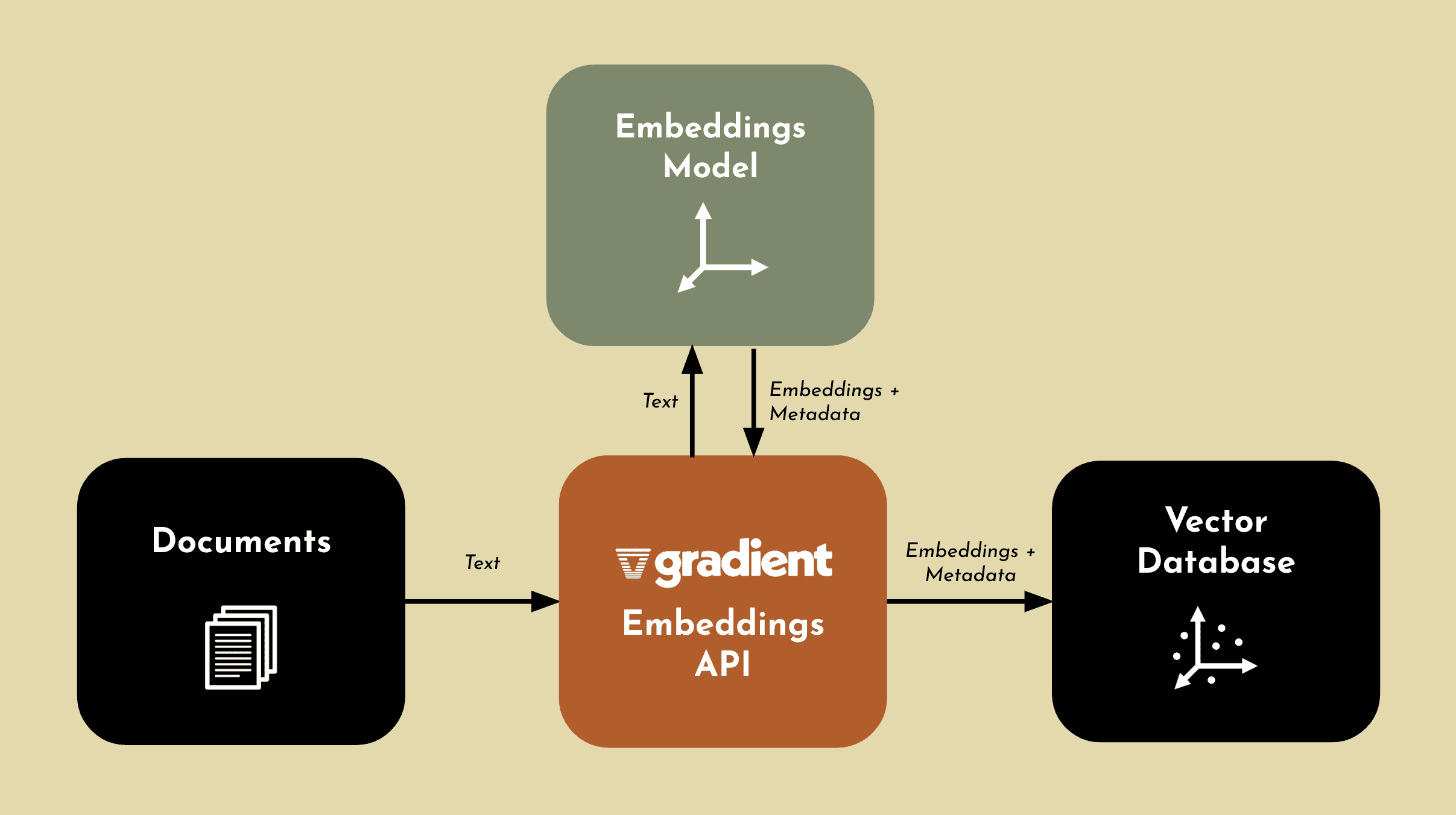
Using the Gradient Embeddings API, you have full control and ownership over your data and generated embeddings. This means you can feel confident using your private data, as no one else can access the embeddings you generate.
Generating embeddings based on your private data makes it easier to perform tasks such as:
Semantic search — An e-commerce website wants to improve its search functionality. When a user searches for “shoes for marathons,” instead of matching keywords, the system understands the user’s intent and recommends shoes designed for long-distance running.
Clustering — A retail store wants to understand customer buying behaviors without any predefined categories. By clustering, they discover some customers regularly buy products, some impulse buy during sales, some only purchase eco-friendly products. By identifying these patterns, the store can tailor marketing strategies for each segment.
Topic modeling — Hospitals receive thousands of patient feedback forms annually. Using topic modeling on this feedback might identify recurring themes or concerns. Topics could include "wait times," "nurse bedside manner," "facility cleanliness," or "quality of food." This can help hospital administrators understand and address the most pressing concerns of their patients.
Classification — A bank wants to predict if a loan applicant is likely to default on their loan based on historical data and customer profiles. They use a classification algorithm to predict "will default" or "won't default" for each applicant. This allows them to make informed decisions about loan approval, manage risk, and potentially reduce the number of bad loans.
See the developer documentation for more details on the product, and visit our pricing page to learn about our pay-as-you-go Embeddings API pricing.
Try Gradient or Join Us
Gradient is now available to independent developers and companies globally. Sign up and get started with $10 in free credits.
Following the free credits, Gradient comes with transparent, token-based pricing. Companies that require tighter security and governance can contact us to learn more and to see a demo.
Developers and organizations only beginning to see the potential of LLMs in various applications, and we’re excited to help them achieve this easier and faster. For anyone looking to join us in this mission, we’re hiring!
Share





