AI Deep Dive
Oct 31, 2023
•
5 min read
Fine-Tuning 101 for Enterprise

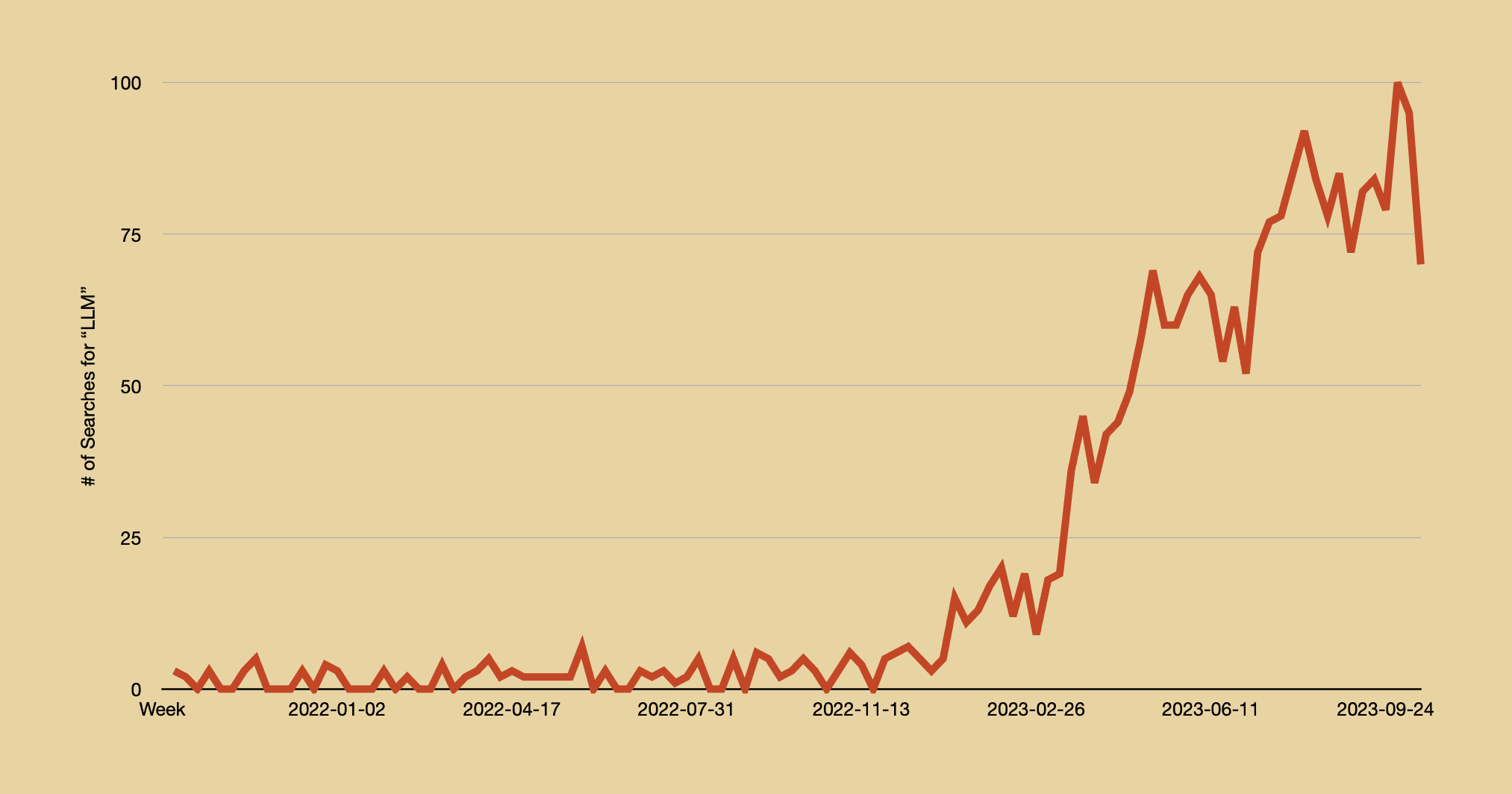
The Rise of LLMs
The interest around Large language models (LLMs) has seen a tremendous increase since 2022, creating new opportunities for businesses through the creation of AI applications. However despite the vast selection of LLMs that are accessible to enterprise businesses, the majority of these models typically lack the expertise and skills necessary to execute against specific tasks in their industry. To overcome these challenges, fine-tuning is often used to enable businesses to customize their LLMs so that they can become experts in their domain and tasks.
What are Large Language Models?
Large language models (LLMs) are essentially deep learning algorithms capable of preforming a wide range of natural language processing (NLP) tasks. Simply put, LLMs are the magic behind what powers your custom AI applications for your business. While there are various LLMs available today, you can generally categorize LLMs into two categories - each with their own advantages and disadvantages.
Closed Source LLMs: Language models that are only accessible behind APIs, which means you’ll only have access to the models outputs. These LLMs are often developed by large corporations and are often proprietary. (e.g. Bard, ChatGPT4, etc.)
Open Source LLMs: Language models whose source code and model weights are publicly available and can be freely accessed, used, modified, and distributed by anyone. (e.g. Llama2, Starcoder, etc.)

What is Fine-tuning?
Most LLMs will come pre-trained and will have already absorbed an extensive amount of data to enable it to understand general language and context. Fine-tuning simply refers to the process of putting your pre-trained model through additional training and adjustments. The goal is simple, which is to train the model to become an expert in the desired domain and acquire the skills necessary to perform specific tasks effectively. For example even though generic LLMs are pre-trained with a vast amount of data, it may not have the necessary skills to execute against specific tasks or domains that the model is unfamiliar with (e.g. complex industries like healthcare or financial services). In the past year alone, we are seeing fine-tuned LLMs enable new opportunities for businesses especially with the creation of an AI workforce to augment their organization.
Internal Knowledge Base: Create experts on your institutional knowledge for your team to unlock the full value of all your data.
Intelligent Operators: Streamline operational processes with models purpose-built for managing key projects, summarizing information, restructuring data, and more.

Why Should Enterprise Businesses Consider Fine-tuning?
Like any business decision, you’ll want to evaluate what’s best for your business. If you’ve decided that you want to build an AI application, the chances are that you’ll need an LLM to power that application. Fine-tuning is a great option to hone your LLM depending on your requirements, the industry you’re in, and what you’re ultimately looking to achieve. This approach can be especially useful if you have limited computational resources and fairly specific tasks. However regardless, fine-tuned LLMs can provide the following benefits:
Enhanced Performance: Fine-tuning enhances the model’s overall performance when it comes to specific tasks - significantly improving accuracy, efficiency, and decision-making.
Cost Effective: Training a single LLM to do everything you want it to do is expensive, since it requires a lot of data and compute hours. Simply put, “don’t boil the ocean”. Fine-tuning is a lot cheaper and requires far less data to train.
Customizable: LLMs are not a one size fits all, which is why fine-tuning tailors your model to address the specific needs and goals of your business.
Domain Specific: Training your model on domain-specific data enables your model to generate accurate responses within the context of the business’s industry.
How to Approach Fine-Tuning
Instruction Tuned Model vs. Completion Model
Instruction-Tuned Model: Fine-tuning an instruction-tuned model involves providing explicit task instructions during training. These instructions guide the model to produce desired outputs, making it a great choice when you need precise control over model behavior.
Completion Model: Completion models are fine-tuned without explicit instructions. Instead, they learn from example data and context, allowing them to generate responses that are more contextually relevant. This approach is useful for more creative tasks but may require more data to achieve the desired results.
Parameter-Efficient Fine-Tuning (LoRA) vs. Full Fine-Tuning
Parameter-Efficient Fine-Tuning (LoRA): LoRA (Low-Rank Adaptation) is a technique that aims to fine-tune models with fewer parameters. It helps maintain model efficiency while adapting it to specific tasks. This approach can be especially useful when you have limited computational resources and you fairly specific tasks.
Full Fine-Tuning: Full fine-tuning involves fine-tuning all of a model's parameters. This approach is suitable when you have ample resources and want to fine-tune a model comprehensively. It often yields better complex task performance but may require more computational power.
Curriculum Learning vs. Single Epoch Training
Curriculum Learning: Curriculum learning is an approach where you fine-tune a model in stages. You start with an easier version of a task and gradually increase its complexity. This helps the model learn progressively and can be beneficial when dealing with tasks that have a learning curve.
Single Epoch Training: In contrast, single epoch training involves fine-tuning the model just once over the entire dataset. This approach is simpler and quicker but may not perform as well on complex tasks compared to curriculum learning.
System Prompt or Not
System Prompt: Using a system prompt is a practice where you provide a predefined starting sentence or phrase to guide the model's generation. System prompts can help set the context and encourage the model to produce relevant outputs. This approach is often used when you want more control over the initial content generated by the model.
No System Prompt: For some tasks, you may opt not to use a system prompt. In such cases, the model generates content from scratch without any initial guidance. This approach can be more challenging but may lead to more creative and diverse outputs.
What Does the Process for Fine-tuning Look Like?
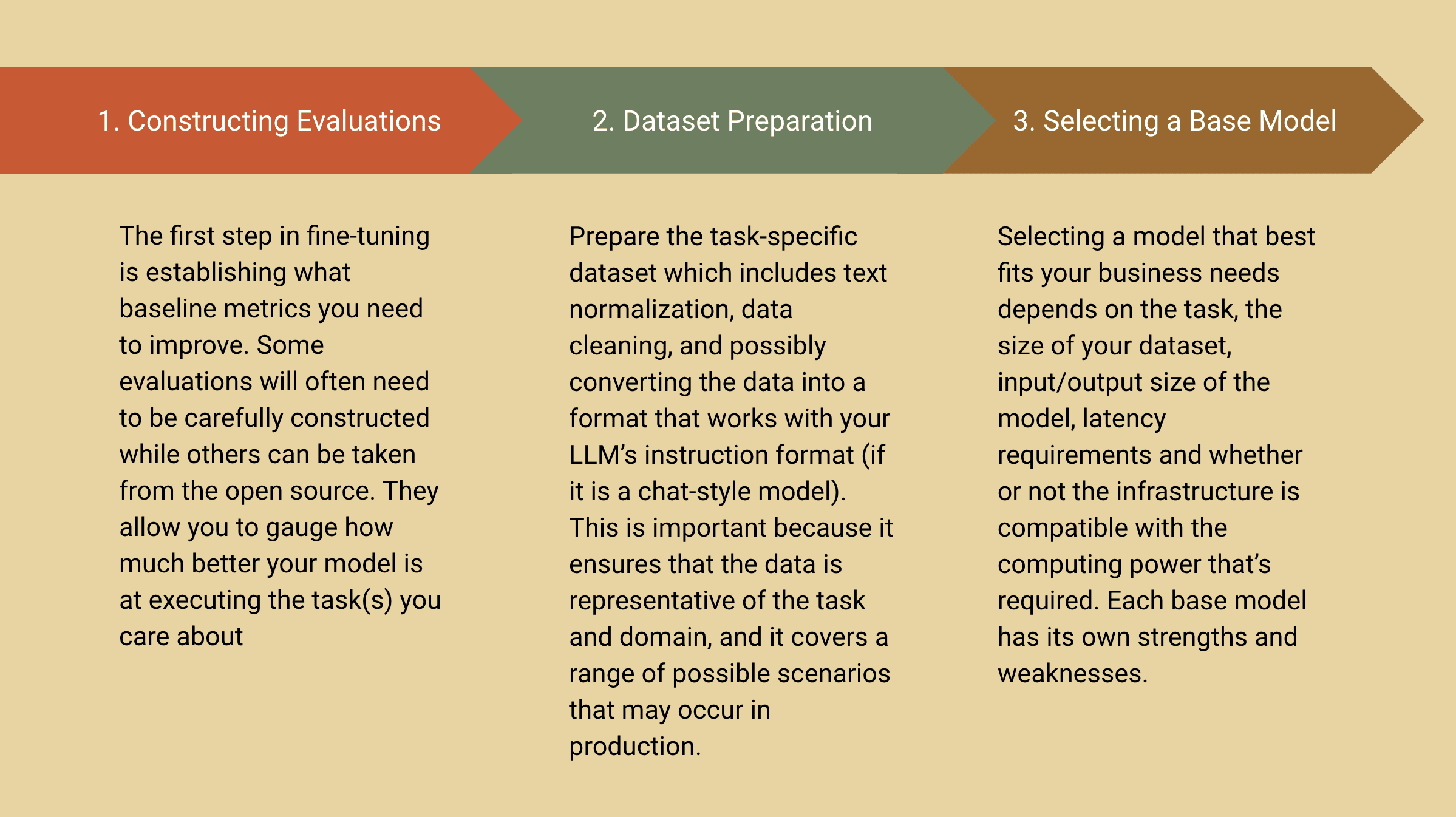
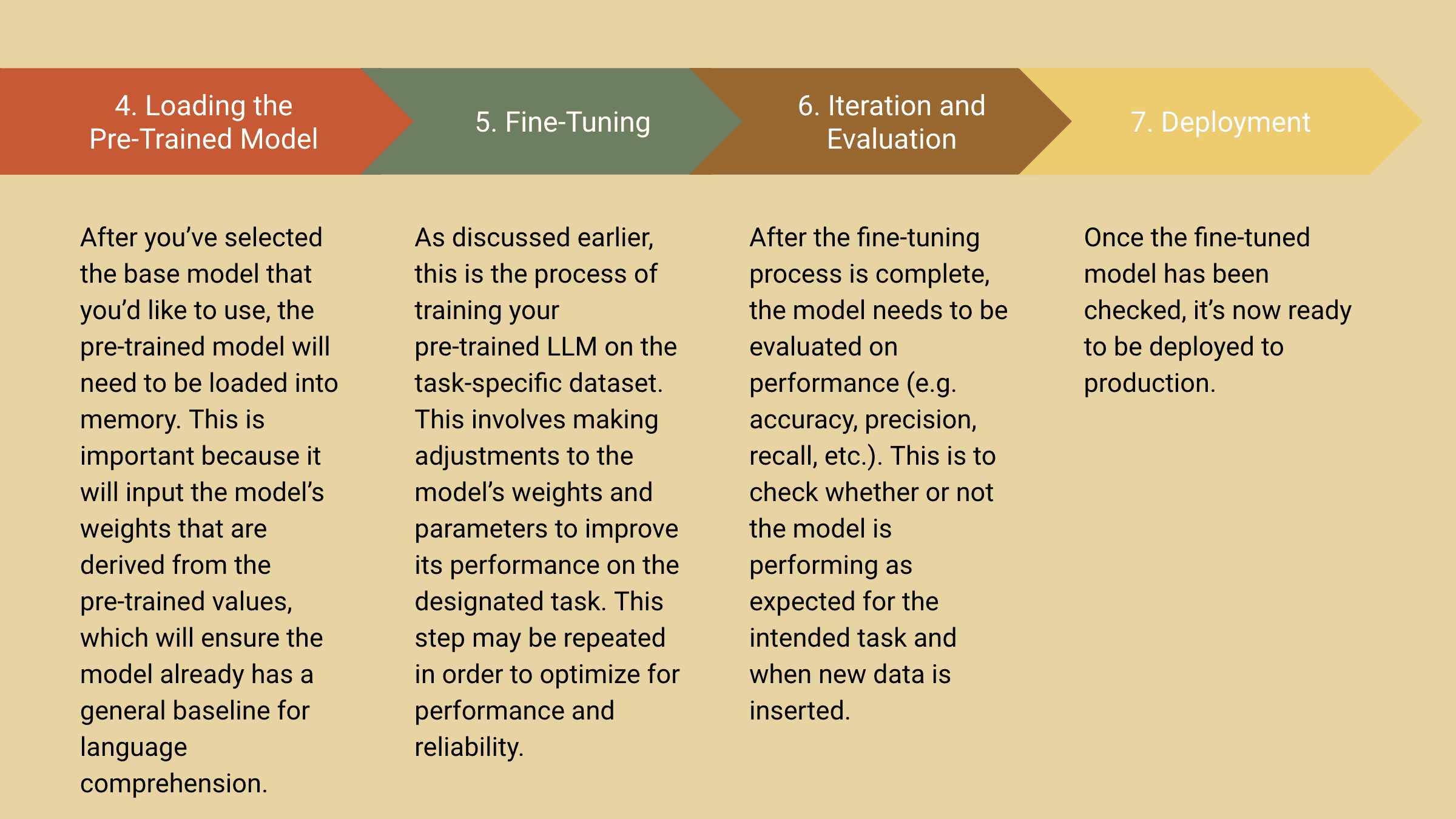
Challenges of Getting Started with Fine-tuning
While fine-tuning is an exceptional way to enhance your models that are used to power custom AI applications, it does come with a few challenges especially if you’re just getting started.
Dedicated Infrastructure: Fine-tuning requires significant computational power, which means you’ll need specialized hardware (e.g. GPUs or TPUs) and a team that understands the space.
Upfront Costs: Given the specialized hardware that’s required for fine tuning, you’ll have a heavy investment upfront and ongoing maintenance to consider.
Difficult to Scale: For enterprise businesses, it’s important that your technology can scale with your business. However one of the biggest challenges when you’re starting out is planning around how much you’ll actually need from the start and how much you’ll need to add along the way.
Developer Expertise: Whenever you’re diving into new technology, it requires your team to have a minimum amount of expertise and understanding. This becomes exponentially harder if your team is not using developer tools or platforms that can simplify the process.
Gradient - One Platform, Unlimited Access to AI
Gradient’s AI Cloud empowers organizations to build, customize, and run private AI solutions on top of highly trained industry specific LLMs. Gradient is the only platform that enables you to combine your private data with LLMs to accelerate AI transformation, while maintaining full ownership of your data and models.
Industry Expert LLMs: Gradient offers a suite of proprietary, state-of-the-art industry LLMs (e.g. Nightingale for healthcare, Albatross for financial services, etc.) and embeddings. These industry expert LLMs are out-of-the-box and highly trained in all aspects of your industry.
Gradient Platform: Gradient also offers a platform to further train these LLMs using your private data, to supercharge your LLMs to understand your organization. Not only is this combination not offered by any other platform today, but Gradient also enables enterprise businesses with the ability to add additional development methods on top of fine-tuning to create an even more effective AI application (e.g. Retrieval Augmented Generation, Prompting, etc.)
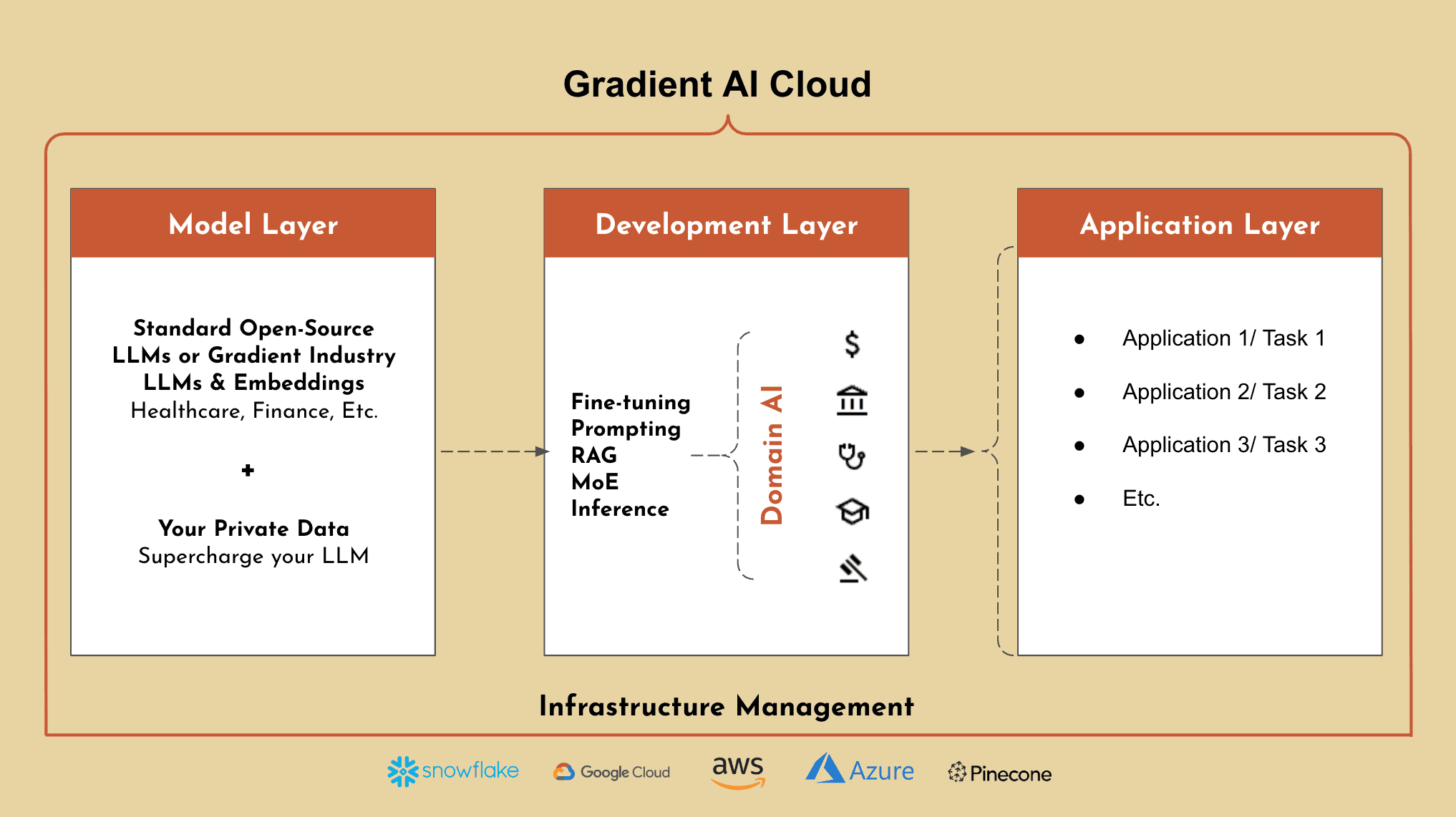
With Gradient, our platform is designed to simplify the development process for AI applications by removing complex infrastructure, upfront costs, and enabling your business to scale confidently.
Host all your models in one place with Gradient’s scalable AI Cloud platform, reducing overhead, maintenance and guaranteeing low latency.
Keep your data in your private environment (dedicated deployments in GCP, AWS, Azure, Snowflake, etc.) and have full ownership and control of the AI models they build
Reduce AI development costs by 70%+, with continued savings in hosting and maintenance costs
Accelerate time to market by 10x with simple infrastructure and state-of-the-art industry models that can be easily customized further based on an organization’s private data
Use developer friendly tools like our partner integrations and simple web APIs to easily fine-tune models, generate completions and embeddings. Our platform is made for developers, simplifying the process to build custom AI applications.
Share





