AI Deep Dive
Oct 3, 2023
The Next Million AI Models: A Mixture of Experts


The Next Million AI Models: A Mixture of Experts
The advent of mobile communication ushered in a new era of technology and human-computer interaction.
Today, cellular connections outnumber humans with nearly 12 billion connected devices that serve over 8 billion people on the planet.
We are on the brink of an even larger technology revolution. Over the past 18 months, we have seen an incredible explosion in the number of large language models.
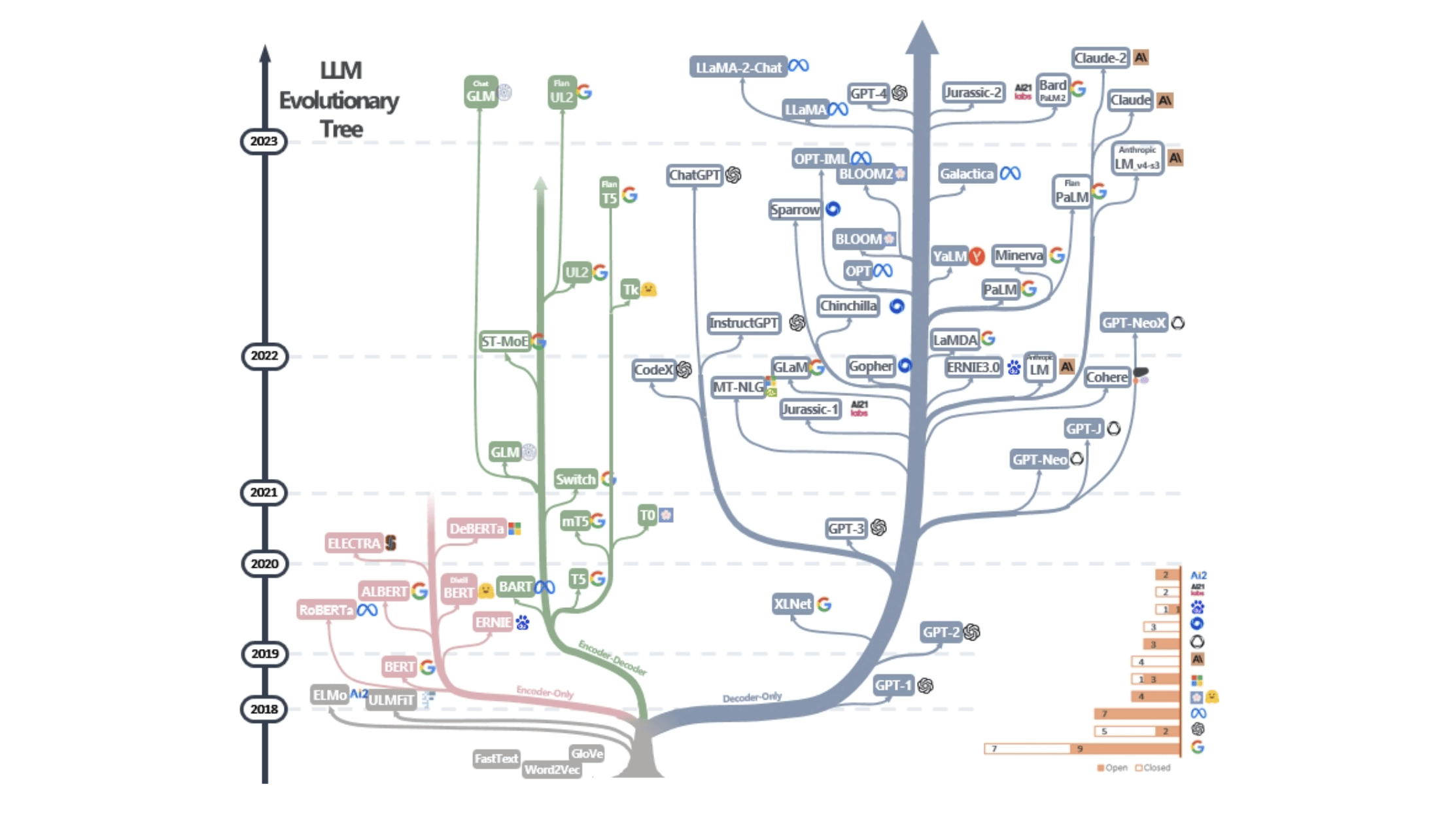
This growth has occurred across the ecosystem from proprietary models like GPT-4 and BARD to open-source models like Llama 2 and Falcon. These advances in AI will be the biggest innovation and technological shift of the 21st century - greater than the advent of mobile computing.
In the next decade, AI models will outnumber humans.
To understand how we will get there, it is critical to understand how we have arrived at this inflection point.
Limitations of Large Language Models
As language models started growing larger, a critical point around 100 billion parameters was discovered. At this size, LLMs started to show emergent behavior. Suddenly, models were completing tasks they had not been trained to perform and the general public took notice. Today, if you ask most people about ChatGPT, they will tell you how it can answer all their questions and help with everyday tasks – almost like magic.
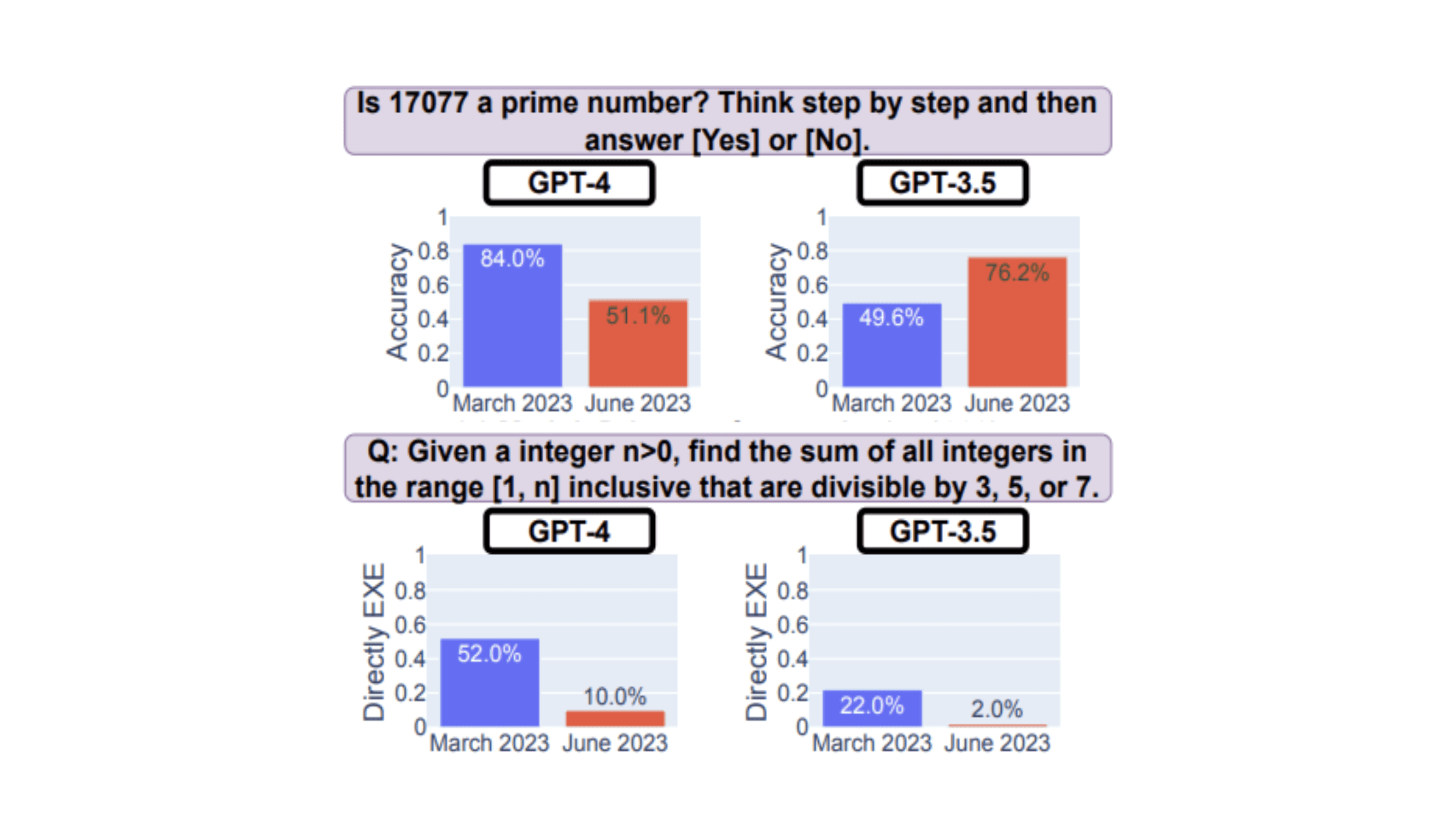
As these large models were further refined, their ability to generate appropriate responses flatlined and even started going downward for certain hyper-specialized tasks. Studies comparing models have shown model performance degrading over time, as illustrated in the graph below.
Smaller, Specialized Models for the Enterprise
Luckily, additional studies have shown that smaller fine-tuned models complete specific tasks better than larger generic models. At the core, this is good news for everyone as organizations no longer need access to proprietary models to achieve best-in-class performance. Instead, smaller open-source models can be fine tuned to meet the company’s needs. These smaller models are cheaper, more efficient, and can outperform their larger counterparts.
If you think about your company’s data lake, it is divided into different departments and sub-groups. This division of data allows for different models to be fine-tuned to meet the needs of each department. Just like how you wouldn’t expect your marketing department to write code, your marketing LLM should be fine tuned to meet a specific set of tasks.
The Mixture of Experts (MoE) Approach to AI
While having smaller models enables better results, having to ask a finance, engineering, product and operations LLM the same question would be tedious and wouldn’t provide a cohesive answer. By employing a Mixture of Experts (MoE) approach, we get the benefits of both large and small models. Similar to how you would ask a group of experts in your company to collaborate on a report, we can ask our models to collaborate on their response.
To illustrate this, consider a simple example. For the prompt given below, we first determine which finely tuned model is most likely to give an appropriate answer. In this case, the answer is most likely to come from engineering, product, or finance. If we take the top-k (where k = 2) and then normalize, we want to weight our answer to be 75% engineering and 25% product. By taking the responses from these two finely tuned models, we can merge them into the final response.
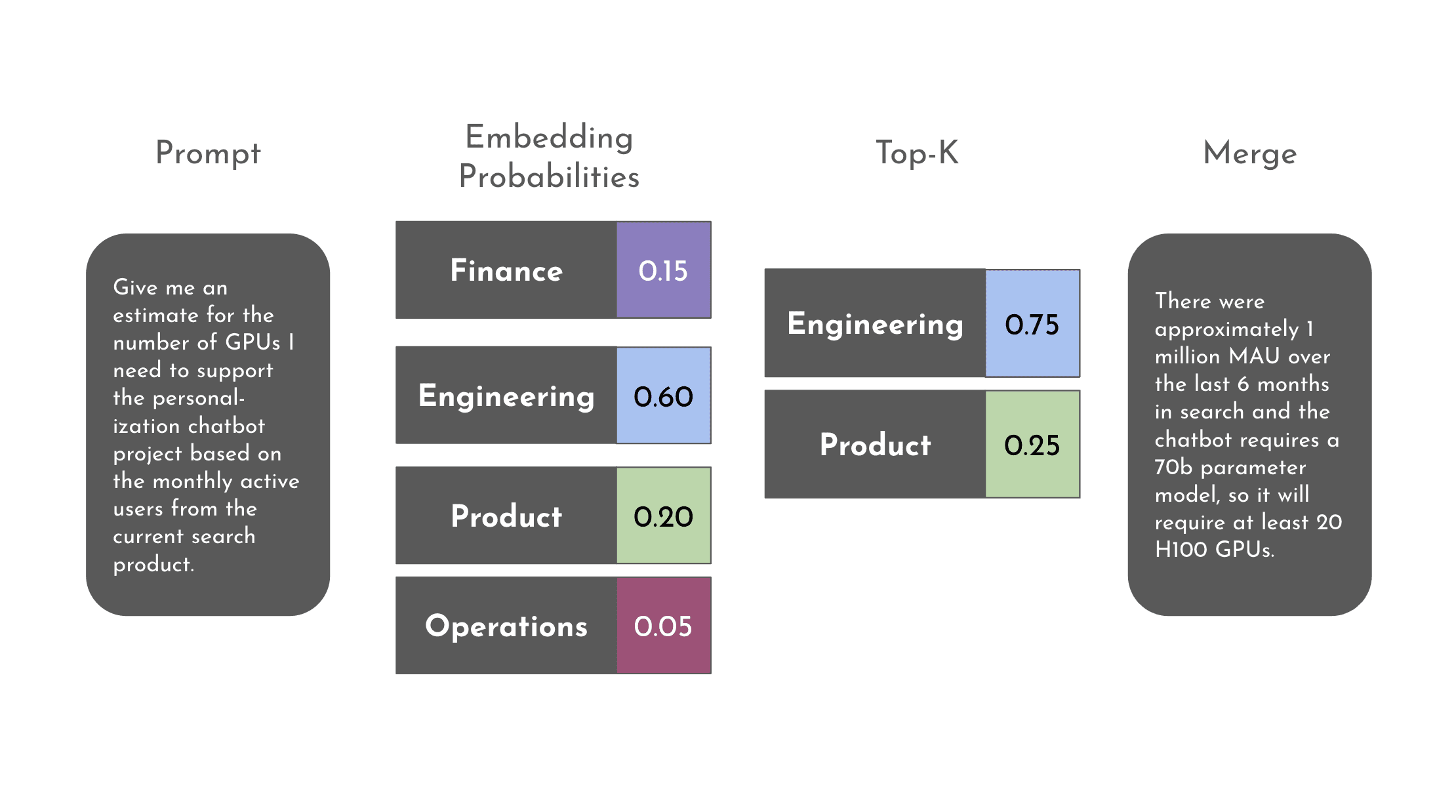
This mixture of experts will further fuel the number of models being created and used. Instead of organizations having a single model, they will have multiple experts they can call upon.
Gradient’s AI Cloud Platform Solution
Gradient can help your organization move to a MoE solution through our AI Cloud Platform by overcoming the three major MoE blockers: complex infrastructure, intricate development, and high costs.
One AI Cloud
Custom AI requires dedicated infrastructure to get started. Host all your models in one place with Gradient’s scalable AI Cloud platform, reducing overhead and guaranteeing low latency.
Simplify Model Development
Gradient fine-tunes state-of-the-art Large Language Models (LLMs) to become experts in your domain—achieving the highest performance on your use cases and accelerating your time to market.
Cost-Effective Development Tools
Scale seamlessly and reduce development costs with Gradient's all-in-one, easy-to-use platform. Build as many custom models you need at no additional cost with our multi-tenant architecture.
About the Author
Sarah Heimlich is the Lead Developer Advocate at Gradient. She previously worked at Google Research as a software engineer and product manager on provable privacy for AI systems. Before Google, Sarah co-founded FIRST Australia and spent a decade growing the program across Australia and the APAC region. In her spare time, you can find her volunteering for the FIRST Robotics Competition as a mentor for team 971 and member of the FIRST California Bay Area Event Planning Committee.
Mark Huang is a Co-founder and Chief Architect at Gradient. Previously, he was a tech lead in machine learning teams at Splunk and Box, developing and deploying production systems for streaming analytics, personalization, and forecasting. Prior to his career in software development, he was an algorithmic trader at quantitative hedge funds where he also harnessed large-scale data to generate trading signals for billion-dollar asset portfolios.
Share





