Creating Financial Chatbots Using Gradient, MongoDB and LlamaIndex
Nov 27, 2023
Gradient Team

Custom AI Applications
One of the most difficult aspects of developing a financial memo is having to sift through large volumes of documents (e.g. reports, transcripts, news, etc.) in order to formulate an investment thesis that can leverages useful insights from the consolidated content. In the past, the typical approach to streamline this process has been to rely on automated workflows that use hardcoded scripts to parse out documents or connect key information with specific entities that are pre-configured.
With the ongoing advancements in AI, there’s an easier and more robust solution to this problem. By using a large language model (LLM) you can develop a sophisticated chatbot that can digest vasts amount of data, in order to provide your team with answers and insights that would otherwise take hours to achieve. To create an application like this, you’ll need an embeddings function to help retrieve the appropriate context that will be passed to your LLM, a vector store for memory, a RAG framework for orchestration and a frontend solution that will be used for the chat interface. Join us as we walk through everything you’ll need to know and consider as you tackle this build.
What is an LLM?
Large language models (LLMs) are essentially deep learning algorithms capable of preforming a wide range of natural language processing (NLP) tasks. Simply put, LLMs are the magic behind what powers your custom AI applications for your business given it’s ability to perform a wide variety of tasks. Despite the power and flexibility that LLMs possess, they are prone to “hallucination” which simply refers to the model’s tendency to respond to a question - regardless of whether or not it actually knows the correct answer. In scenarios such as financial analysis, accuracy is so paramount that “hallucination” often cannot be tolerated.
Retrieval Augmented Generation
For those who have worked with LLMs in the past, the responses that are generated from a foundational LLM may often times seem accurate at first glance. However even LLMs that are trained with a vast amount of data are known for their ability to generate inaccurate or nonsensical responses - widely referred to as hallucinations.
To reduce LLM hallucination and improve the quality of LLM generated responses, retrieval augmented generation (RAG) is often used. RAG grounds the model on external sources of knowledge to supplement the LLM’s internal representation of information. Simply put, RAG blends the best of both worlds from retrieval-based and generative systems. Instead of generating responses from scratch, it fetches relevant documents that contain domain specific context and uses them to guide the response generation.
To build this chatbot we will be using RAG and leveraging Gradient as the platform to bridge all the different technologies that will be used to bring this application to life. With Gradient, developers and enterprise businesses can easily build, customize, and run private AI applications, while maintaining full ownership of their data and models.
Host all your models in one place with Gradient’s scalable AI Cloud platform, reducing overhead, maintenance and guaranteeing low latency.
Keep your data in your private environment and have full ownership and control of the AI models they build
Reduce AI development costs by 70%+, with continued savings in hosting and maintenance costs
Accelerate time to market by 10x with simple infrastructure and state-of-the-art industry models that can be easily customized further based on an organization’s private data
Use developer friendly tools like our partner integrations and simple web APIs to easily fine-tune models, generate completions and embeddings. Our platform is made for developers, simplifying the process to build custom AI applications.

Step 1: Download Financial Reports and Read the Raw PDFs Into Texts
LlamaIndex comes with one of the easiest ways to load a PSF into a raw string. (data_dir will be the folder containing ALL the pdfs)
One example report that we’ll be using is the AMD 2023 Q3 Report shown below.

Step 2: Connect to Gradient LLM and Embeddings
Since Gradient provides simple web APIs, you can easily fine tune models, generate completions and embeddings all from one platform. To get started, you’ll have to create an account on Gradient to generate an access token.
You will also need to have a workspace id that is automatically created when you first sign up.

Gradient provides each user with a $5 workplace credit so you’ll be able to get started on the platform immediately. From there you can easily create an LLM and Embeddings connection to make requests to the Gradient Model and Embeddings API.
Step 3: Create a Connection to MongoDB Atlas
Atlas Vector Search is a comprehensive managed solution that streamlines the indexing of high-dimensional vector data in MongoDB. It enables quick and efficient vector similarity searches, reducing operational overhead and simplifying the AI lifecycle with a single data model. This service allows you to either utilize MongoDB Atlas as a standalone vector database for a fresh project or enhance your current MongoDB Atlas collections with vector search capabilities.
To get started, create an Atlas account and create a cluster.
You’ll have to first create an Index in the UI before you can use it to store embeddings and document chunks. Since we’ll be using the bge-large-v1.5 Embeddings model, we’ll also need to specify our embeddings dimension (1024) within the index config.
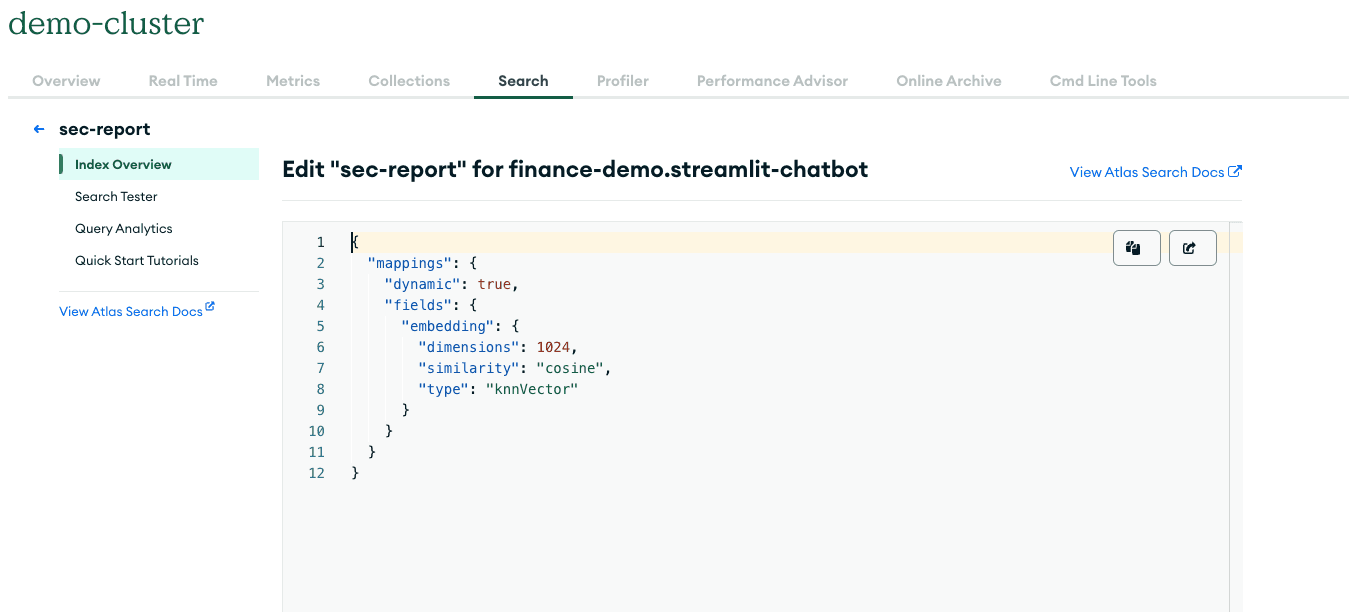
Once you’ve completed that step, you’ll need to create a pymongo client to connect to a MongoDBAtlasVectorSearch so that you can use it as the backend storage in the VectorStoreIndex.
Step 4: Create a Chat Engine Using LlamaIndex
Using LlamaIndex we can bring together all the elements that are involved with context retrieval, using a combination of Gradient Embeddings and MongoDB Atlas, while using the Gradient LLM (specifically nous-hermes2) to generate completions. As a result our chatbot will respond with an accurate response that’s “grounded”, using the knowledge that the model has obtained from the vast amount of financial documents that were provided. To learn more about our integration with LlamaIndex, check out our developer documentation here.
Step 5: Chat Over the Documents in our Streamlit App
The full Streamlit App can be found in this repository.
After deploying the Streamlit App you can start using the chat interface to ask questions about the financial reports from AMD, Intel, Nvidia and TSMC. The chatbot will have limited memory functionality, but it should still be able to recall previous dialogue history in order to respond to follow up questions without having to repeat the entire prompt.
