Archive
Oct 17, 2023
•
5 min read
Retrieval Augmented Generation (RAG) with Gradient Embeddings

RAG: A Quick Primer
Retrieval Augmented Generation (RAG) blends the best of both worlds from retrieval-based and generative systems. Instead of generating responses from scratch, it fetches relevant documents and uses them to guide the response generation.
RAG has been shown to be useful to prevent LLM hallucinations. An April 2021 paper explores this: Retrieval Augmentation Reduces Hallucination in Conversation. RAG also allows the model to cite its sources and improves auditability.
RAG vs. Fine-Tuning
You’ll often hear the debate - should I use fine-tuning or RAG? At Gradient, we believe the answer isn’t one or the other, but rather it’s a combination of both. Combining RAG and fine-tuning significantly enhances the performance and reliability of your LLM. RAG enables your LLM with the ability to access an external knowledge base, providing your model with enough context to elicit the capability that it was trained to do - a concept known as in-context learning. Whereas fine-tuning on the other hand, represents the process of training your model to acquire the necessary skills to perform the task. While there may be a chance that the intended task could be accomplished by using only one of these methods, LLMs perform exponentially better when it has the right context and the necessary skill to tie together the best possible response for the completion.
How the Gradient Embeddings API Enables RAG
The Gradient Embeddings API allows you to easily create embeddings based on your data. You can input words, phrases or even the text of full documents and get an embedding in return. These embeddings can be stored in a vector database of your choice.
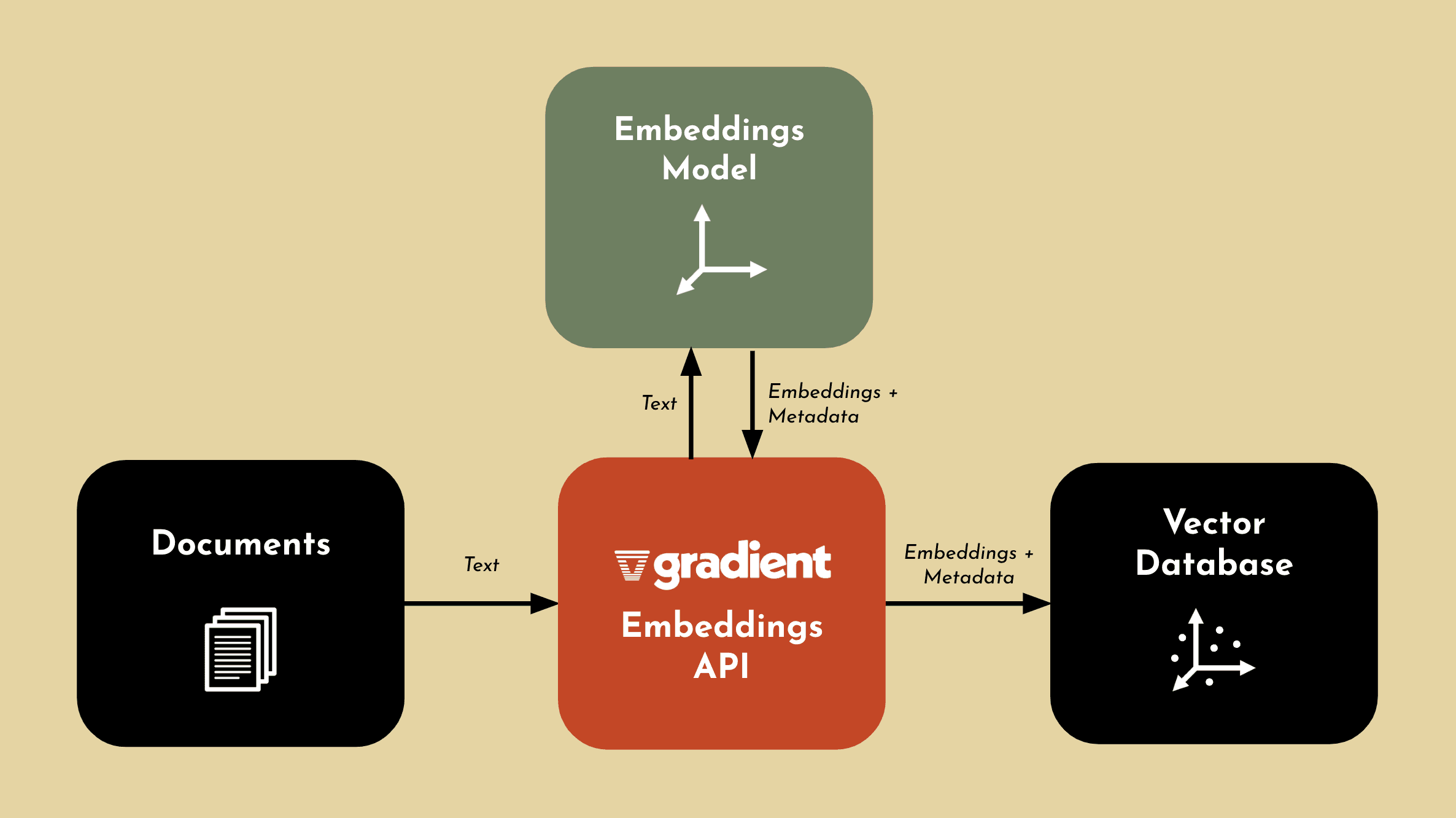
Once you have built out your new knowledge base (embeddings in a vector database), you can generate completions using this additional context.
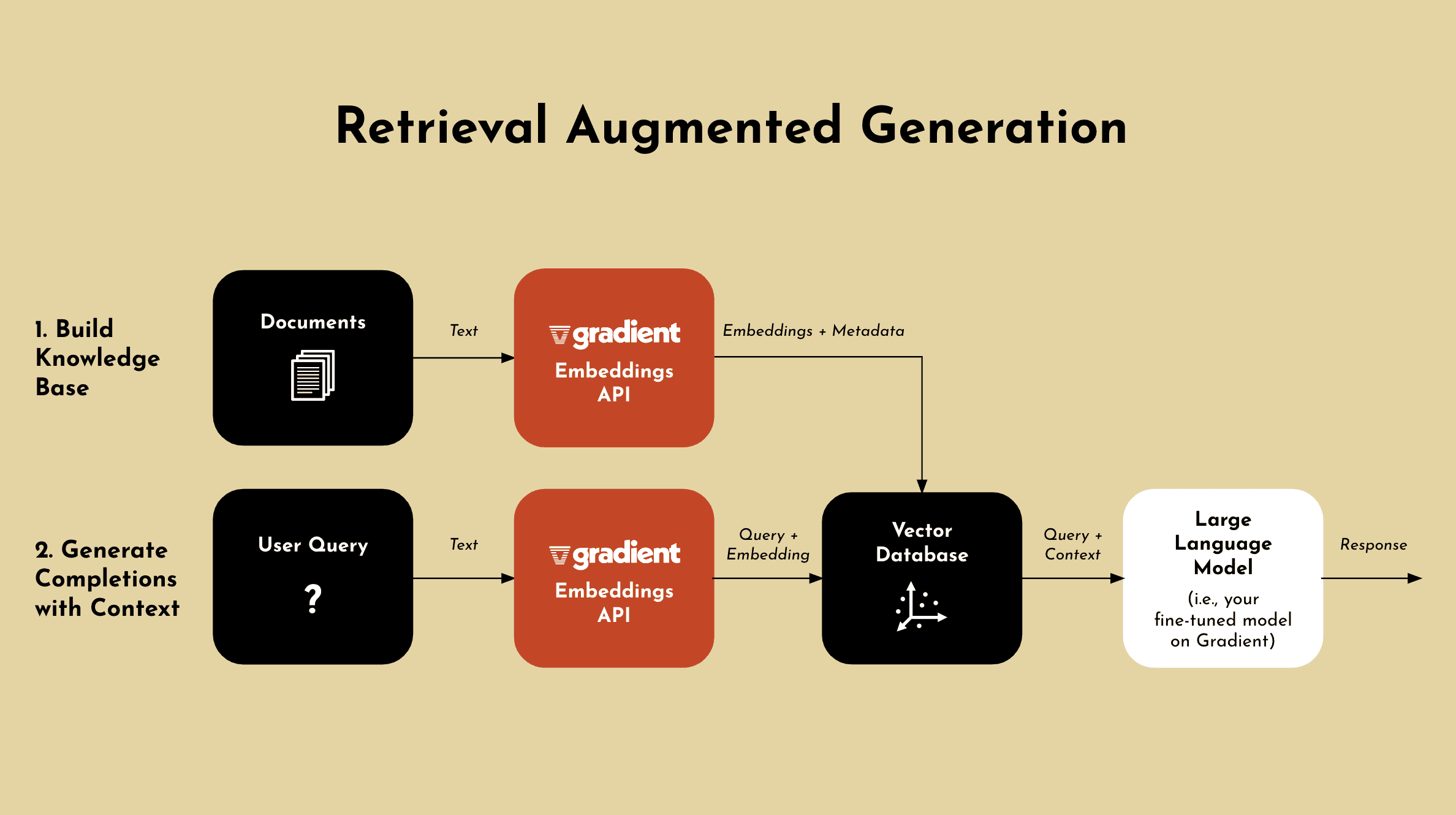
When a user submits a query, the Gradient Embeddings API converts the text into an embedding. You can then retrieve semantically relevant data from the vector database, and the LLM generates a response based on the additional information.
Simplifying RAG with LlamaIndex
Last week we announced our integration with LlamaIndex, enabling users to effectively implement RAG on top of their private, custom models in the Gradient platform. While the overall process for RAG with LlamaIndex will remain relatively the same from what we’ve already discussed, what you get in return is something you should definitely consider. Not only will the process become significantly easier, but LlamaIndex allows for far more sophisticated indexing and retrieval of context due to their cutting edge methods that they use to perform RAG.
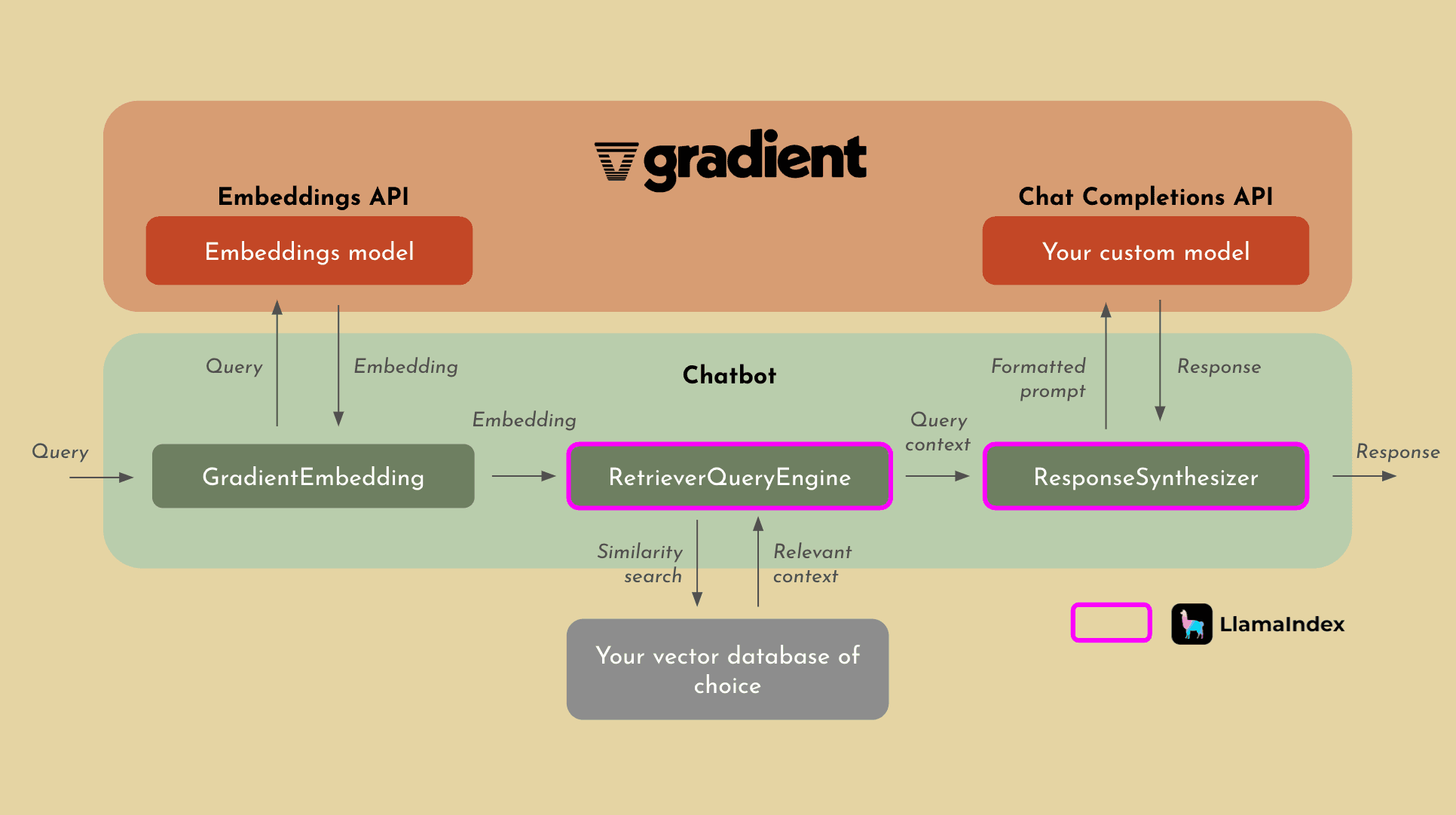
Applications of Gradient-Enabled RAG
Using the Gradient Embeddings API, you have full control and ownership over your data and generated embeddings. This means you can feel confident using your private data, as no one else can access the embeddings you generate.
Generating embeddings based on your private data makes it easier to build applications such as:
Customer support chatbots — The chatbot can retrieve the latest available information and generate an up-to-date, tailored answer based on those resources.
Enhanced search and content discovery — With RAG, you can build a more intelligent search system that can retrieve and generate concise answers or summaries from vast amounts of data. For example, if an employee wants to know the company's policy on remote work, they can get a summary based on relevant sections of the company’s policy documents.
Financial analysis — Using RAG, LLMs can pull the latest financial data or news snippets from a constantly updated database, and then generate a comprehensive analysis. This ensures businesses and analysts receive current insights, allowing them to make informed decisions
Recommendations: LLMs can retrieve the most recent or pertinent articles from a database and then generate personalized content recommendations. This ensures that users receive up-to-date and highly relevant content suggestions, enhancing user experience and engagement.
Try Gradient Embeddings and LlamaIndex
Sign up and get started with $5 in free credits.
See the developer documentation for more details on Gradient Embeddings and our latest integration with LlamaIndex.
Share





